# 数据集成说明文档
# 1 模块及功能概述
数据集成这一模块是面向开发人员的数据迁移工具,是数据的搬运工,以支撑TC、施工、造价、新金融等业务线的数据接入做为主要目标。
# 2 应用场景
施工业务线的产品数据接入,为施工方各BI产品提供数据服务。
# 3 快速指南
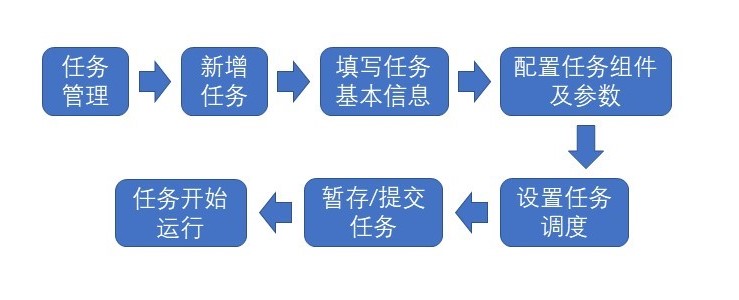
# 4 名词解释
数据集成任务/任务:数据集成任务就等于数据集成模块下面的任务,指的是能完成一个完整的数据集成/数据迁移/数据接入的任务。任务下面会有基本信息、流程、调度、日志等属性。
流程/任务流程:(任务)流程指的都是一个数据集成任务的数据接入、数据处理的整个流程。它包含一个或者多个流程组件。
组件/流程组件:(流程)组件指的是一个数据集成任务中的最小单元,按照组件的类型不同可以分为输入组件、输出组件、转换组件等。一个或者多个组件组成了整个数据集成任务。
流程模板:流程模板是在创建一个新的数据集成任务时需要选择的任务预先配置的一套组件信息。比如MySQL到PostgreSQL流程模板就会包含一个MySQL读取组件和一个PostgreSQL写入组件。模板只是创建一个新任务的初始状态,基于流程模板创建后,还可以在任务的流程配置页面对任务流程所包含的组件进行新增和删除。
数据源/数据来源/数据目标:数据源(Data Source)指的是各种类型的数据存储实质。按照数据生产和数据消费又可以分为数据来源(数据的生产方),数据目标(数据的消费方)。
# 5 用户指南
5.1 导航栏
数据源管理:所有数据集成任务需要用到的数据源Data Source;
任务管理:数据集成任务的新建、修改、删除、订阅等;
组件管理:数据集成组件的新建、修改、删除、发布等。
5.2 数据源管理
在数据源管理中,用户可以对数据源进行新建、删除、配置和查询操作,并将完成配置的数据源作为任务流程中的数据来源和数据目标。当前版本(Sprint3)中,数据集成模块支持MySQL、PostgreSQL、MongoDB和HTTP数据类型。
新建:新建数据源,并对其进行配置,如下表所示,基础配置内容包括名字、描述和数据源类型,MySQL、PostgreSQL和MongoDB数据类型还需要配置服务器信息、数据库名、登录数据库的用户名和密码(服务器信息填写格式为IP或IP:port,当有多个IP地址时,可用“,”进行分隔,如:1.1.1.1:8080,1.1.1.2:9000),此外MongoDB还需要填写认证库信息;HTTP数据类型则需要填写数据连接信息和访问令牌。
此外,可通过高级选项对数据源的其他连接参数进行设置。
例如:
replicaSet: mgset-20769481
stringtype: unspecified
2
| 数据源类型 | 基础配置信息 | 配置信息 | 高级选项 | ||
| MySQL | 名字(必填) | 描述 | 数据源类型 | 服务器信息、数据库名、登录用户名和密码 | |
| PostgreSQL | |||||
| MongoDB | 服务器信息、数据库名、登录用户名和密码、认证库 | ||||
| HTTP | 数据连接信息、访问令牌 | ||||
详情:查询已配置完成的数据源信息,并可进行修改。在新建与详情中都可就目前填写的配置信息进行连接测试,测试包括GDC后端服务器与数据源服务器连接测试和数据集成执行引擎与数据源服务器连接测试。
删除:删除已配置的数据源信息。
5.3 任务管理
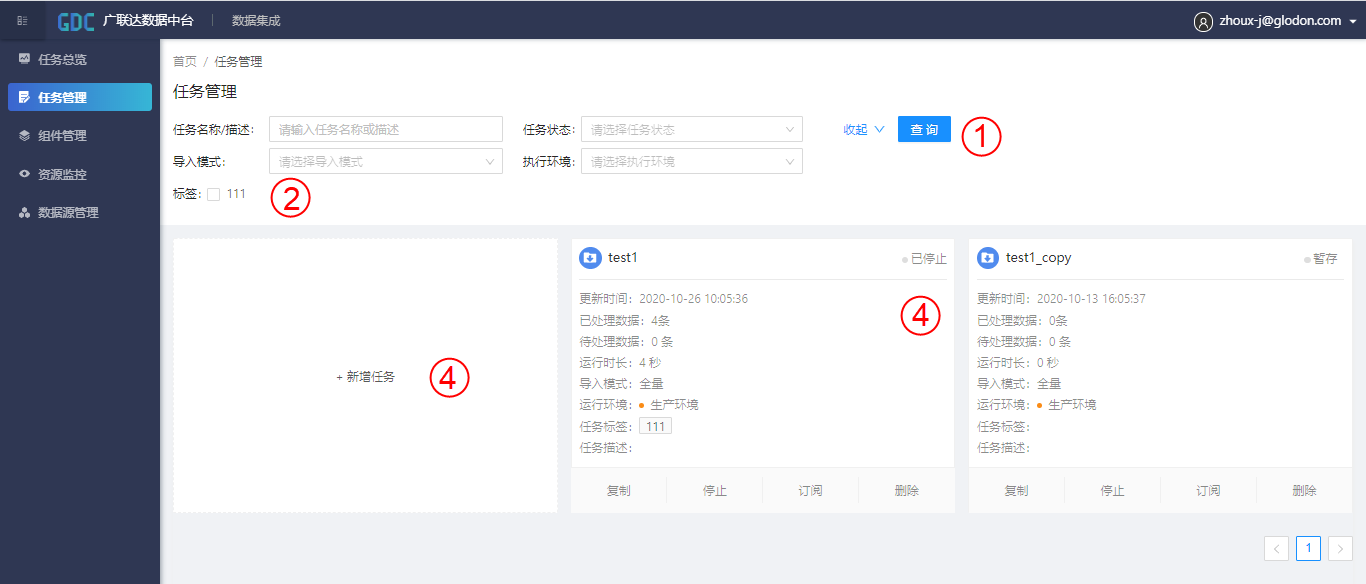
① 任务管理的搜索栏,可根据任务流程名称和描述中包含的字符、任务状态、导入模式及执行环境对任务流程进行搜索,任务状态包括暂存、未开始、运行中、已暂停和已停止;导入模式包括增量和全量;执行环境目前只包括生产环境一个选项;
② 标签复选框,可通过勾选标签对任务进行筛选过滤;
③ 任务列表,仅展示个人创建的任务信息,可进行筛选过滤,展示的任务信息包括更新时间、已处理数据、待处理数据、运行时长和任务描述,同时也可以对流程进行复制、停止、订阅和删除操作;
④ 新增任务。
5.3.1 新增任务
在点击新增任务后,需要填写任务名称(必填)、流程模板(必填)、任务类型(必填,正式和测试)、导入模式(必填,增量和全量)和任务描述,目前支持的流程模板有:
- 单表-JDBC-导入到数据中台
支持数据由从JDBC类的数据源的单个表导入到数据中台的单个模型。 - 单表-MongoDB-导入到数据中台
支持数据由从MongoDB的数据源的单个表导入到数据中台的单个模型。 - 单表-MySQLBinlog-同步到数据中台
支持CDC模式的数据接入方式,通过正则模式匹配MySQL的数据库/表同步到数据中台的单个模型。 - 单表-MongoOplog-同步到数据中台
支持CDC模式的数据接入方式,通过正则模式匹配MongoDB的数据库/集合同步到数据中台的单个模型。 - 模式匹配-MySQL-合并到数据中台
支持通过正则模式匹配MySQL的数据库/表,合并成一个表,写入到数据中台的单个模型中。(备注:必须要保证正则模式匹配的多个表的表结构一致)。 - 模式匹配-MySQLBinlog-推送到数据中台Kafka
支持CDC模式的数据接入方式,通过正则模式匹配MySQL的数据库/表同步到数据中台的Kafka消息队列。 - 模式匹配-MongoOplog-推送到数据中台Kafka
支持CDC模式的数据接入方式,通过正则模式匹配MongoDB的数据库/集合同步到数据中台的Kafka消息队列。 - 单表-HTTP(AECORE)-导入到数据中台
支持通过HTTP请求获取AECORE的单个表数据,写入到数据中台的单个模型中。 - 单表-JDBC-导入到JDBC
支持数据由从JDBC类的数据源的单个表导入到JDBC类的的单个表。 - 单表-MongoDB-导入到JDBC
支持数据由从MongoDB的数据源的单个表导入到JDBC类的的单个表。 - 单表-MySQLBinlog-同步到JDBC
支持CDC模式的数据接入方式,通过正则模式匹配MySQL的数据库/表同步到JDBC类数据源的单个模型。 - 单表-MongoOplog-同步到JDBC
支持CDC模式的数据接入方式,通过正则模式匹配MongoDB的数据库/集合同步到JDBC类数据源的单个模型。 - 单表-MongoOplog-同步到JDBC(无序)
支持CDC模式的数据接入方式,通过正则模式匹配MongoDB的数据库/集合同步到JDBC类数据源的单个模型。(备注:这个是无序且多线程写入,提升了效率)。 - 单表-MySQLBinlog-同步到JDBC(无序)
支持CDC模式的数据接入方式,通过正则模式匹配MySQL的数据库/集合同步到JDBC类数据源的单个模型。(备注:这个是无序且多线程写入,提升了效率)。 - 模式匹配-MySQL-合并到JDBC
支持通过正则模式匹配MySQL的数据库/表,合并成一个表,写入到JDBC的单个模型中。(备注:必须要保证正则模式匹配的多个表的表结构一致)。 - 单主题-Kafka-导入到HDFS
支持读取Kafka单个topic的数据,写入到HDFS的单个路径下。
5.3.2 任务流程订阅
在任务管理界面,可以对任务列表中的任务流程进行订阅,如Fig 3所示。

订阅功能为对所选任务在每五分钟内产生的日志进行整理并发送至订阅邮箱。
根据任务日志内容的四个等级(详见7.2任务日志),我们可以对接收邮件的内容进行选择,以及可以选择是否订阅数据来源的元数据变更信息。
5.4 组件管理
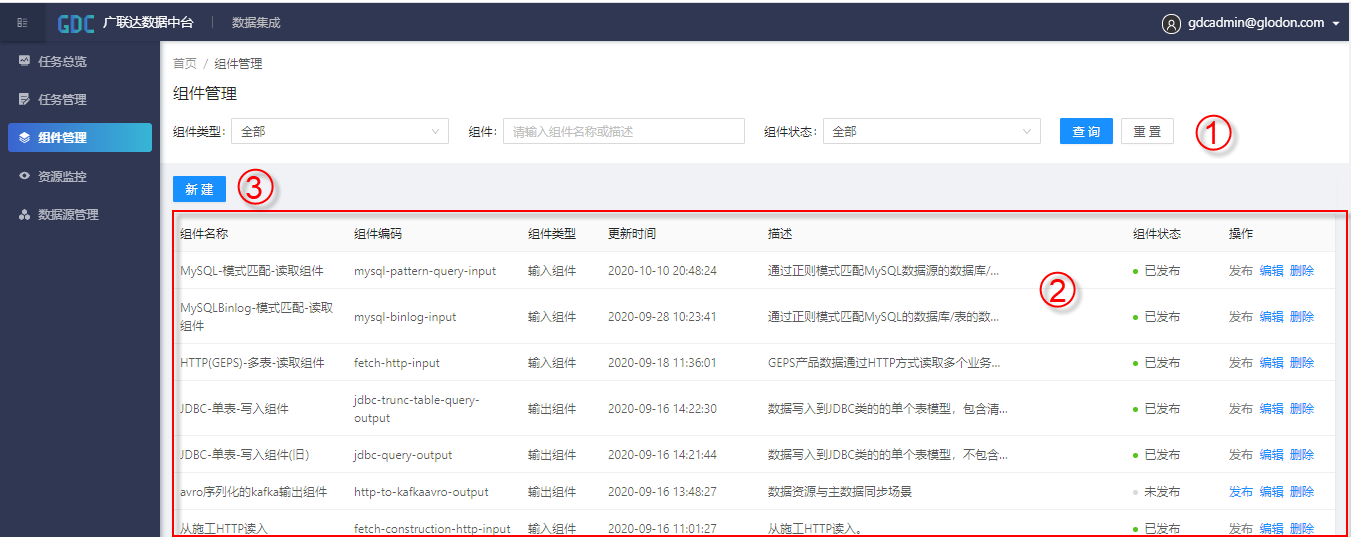
组件管理界面如Fig 4所示。
组件管理界面仅能由超级管理员查看,其他一般账户无权限访问。
①组件管理的搜索栏,可根据组件类型、组件名称和描述中包含的字符以及组件状态对组件进行搜索,组件类型包括输入组件、输出组件和转换组件;组件状态包括已发布和未发布;
②组件列表,可以查看到当前搜索条件的组件信息,包括组件名称、组件类型、更新时间、描述、组件状态,同时也对组件进行发布、编辑和删除操作;
③新增组件。
新增组件:在点击新增组件后,除需要填写组件名称(必填)、组件类型(必填)、组件描述三个基本信息外,还需要上传组件的XML文件,为确保其他用户能正常使用新增的组件,请添加简洁明了的参数说明并定期维护。
目前组件如下表所示:
| 组件名称 | 组件编码 | 组件类型 |
| JDBC-单表-读取组件 | jdbc-query-input | 输入组件 |
| MongoDB-单表-读取组件 | mongo-query-input | |
| MySQLBinlog-模式匹配-读取组件 | mysql-binlog-input | |
| MongoOplog-模式匹配-读取组件 | mongo-query-oplog-input | |
| MySQL-模式匹配-读取组件 | mysql-pattern-query-input | |
| HTTP(GEPS)-多表-读取组件 | fetch-http-input | |
| Kafka-单主题-读取组件 | kafka-consume-input | |
| HTTP(AECORE)-单表-读取组件 | aecore-http-input | |
| HTTP(GDC)-视图API单表-读取组件 | fetch-construction-http-input | |
| 数据中台-单表-写入组件 | jdbc-query-output | 输出组件 |
| JDBC-单表-同步组件 | jdbc-standard-output | |
| JDBC-单表-写入组件 | jdbc-trunc-table-query-output | |
| JDBC-单表-同步组件(无序) | jdbc-standard-output(unsorted) | |
| JDBC-批量-写入组件 | geps-output | |
| HDFS-单路径-写入组件 | hdfs-output | |
| 字段转换组件 | jslt-transform | 转换组件 |
| JSON拆分组件 | json-split-transform |
# 6 组件介绍
在本节中将会对当前已发布的所有组件进行介绍,主要分为功能介绍,简单模式配置方法,高级模式配置方法,并为7.3流程模板介绍中的任务流程配置做基础。
6.1 jdbc-query-input(JDBC-单表-读取组件)
从JDBC类的数据源读取单个表模型的数据。
这是一个输入组件,主要功能为JDBC类的数据源执行SQL查询语句,可以进行全量查询或增量查询。目前,增量查询时,可以查询任务执行时过去一天的数据。
| 信息名称 | 描述 | 范例 |
|---|---|---|
| 数据来源名称 | 下拉菜单格式,选择内容为在数据源管理中已配置完成的MongoDB数据源 | |
| 数据表/模型 | 在所选择的SQL类数据源中需要读取的表名 | |
| 模式 | 下拉菜单格式,选择增量/全量 | |
| 过滤条件 | 查询数据的筛选条件 | "_id":123456,"category":"lan" |
| 增量字段 | 增量模式下必填,全量模式下不填,所选字段需为时间格式,会对当前运行任务时间昨天的数据进行查询 | update_time |
jdbc-query-input组件高级模式规则:
| reference: | |
| type: DATA_SOURCE | |
| id: 5ebd367d78020e67021fb1c8 | //数据源ID |
| mode: full | //全量模式,增量模式为incremental |
| filter: '' | //过滤条件,此处为对查询数据不筛选 |
| selected.fields: '' | //查询返回的字段,多个用','隔开,全部用'' |
| table.name: testab | //数据表 |
| incremental.field: | //增量查询的字段,增量模式下必填,全量模式下不填 |
6.2 mongo-query-input(MongoDB-单表-读取组件)
从MongoDB数据源读取单个表模型的数据。
这是一个输入组件,主要功能为从MongoDB中查询数据,可以进行全量查询或增量查询。目前,增量查询时,可以查询任务执行时过去一天的数据。
| 信息名称 | 描述 | 范例 |
|---|---|---|
| 数据来源名称 | 下拉菜单格式,选择内容为在数据源管理中已配置完成的MongoDB数据源 | |
| 集合名 | 在所选择的MongoDB数据源中需要读取的collection名称 | |
| 模式 | 下拉菜单格式,选择增量/全量 | |
| 过滤条件 | 查询数据的筛选条件 | "_id":123, "category":"lan" |
| 结果集 | 对查询结果进行设置 | 去掉_id字段: {"_id":0},全部字段:{} |
| 增量字段 | 增量模式下必填,全量模式下不填,所选字段需为时间格式,会对当前运行任务时间昨天的数据进行查询 | update_time |
mongo-query-input组件高级模式规则:
| reference: | |
| type: DATA_SOURCE | |
| id: 5ec609320149d45eeb9dbec8 | //数据源ID |
| mode: incremental | //增量模式,全量模式为full |
| filter: ''"num":99990' | //过滤条件,此处过滤条件为 读取数据中num字段为99990的文件 |
| collection.name: lxy_test | //集合名 |
| projection: '{}' | //结果集,此处为保留全部字段 |
| incremental.field: time | //增量字段,此处查询的增量字段为time |
6.3 mysql-binlog-input(MySQLBinlog-模式匹配-读取组件)
通过正则模式匹配MySQL的数据库/表的数据(CDC模式的数据接入方式)。
这是一个输入组件,通过MySQL-Binlog来获取MySQL数据的变动信息,包括begin、commit、ddl、delete、insert、update信息。利用mysql-binlog-input组件,可以做到MySQL数据源间的数据同步。
| 信息名称 | 描述 |
|---|---|
| 数据来源名称 | 下拉菜单格式,选择内容为在数据源管理中已配置完成的MySQL数据源 |
| 库名称正则 | 所选择的MySQL数据源对应URL下要读取的库名称 |
| 表名称正则 | 对应库下需要读取的表名称 |
mysql-binlog-input组件高级模式规则:
| reference: | |
| type: DATA_SOURCE | |
| id: 5ec76a34634a6d671f96fa9a | //数据源ID |
| database.name.pattern: fxl_test | //库名称正则 |
| table.name.pattern: test | //表名称正则 |
| retrieve.all.records: true | //是否从头读取binlog,如果该值为true,则不用 //设置use.binlog.gtid、initial.binlog.gtid、 //initial.binlog.filename和initial.binlog.position |
| use.binlog.gtid: 'false' | //是否启用mysql集群的gtid(当前版本未启用) |
| initial.binlog.gtid: '0' | //设置起始读取的gtid,如果use.binlog.gtid为false, /该参数无效(当前版本未启用) |
| initial.binlog.filename: default | //设置起始读取的binlog文件名,如果use.binlog.gtid //为true,该参数无效(当前版本未启用) |
| initial.binlog.position: '0' | //设置起始读取的binlog的位置,如果use.binlog.gtid为true,该参数无效(当前版本未启用) |
6.4 mongo-query-oplog-input(MongoOplog-模式匹配-读取组件)
通过正则模式匹配MongoDB的数据库/表的数据(CDC模式的数据接入方式)。
这是一个输入组件,通过Momgo-Oplog来获取Mongo数据的变动信息,支持数据的“增、删、改”信息。利用mongo-query-oplog-input组件,可以做到由MongoDB数据源到SQL类数据源的数据同步。
| 信息名称 | 描述 |
|---|---|
| 数据来源名称 | 下拉菜单格式,选择内容为在数据源管理中已配置完成的SQL类数据源 |
| 源库名称正则 | 所选择的SQL类数据源对应URL下需要读取的库名称 |
| 集合名正则 | 对应库下需要读取的表名称 |
mongo-query-oplog-input组件高级模式规则:
| reference: | |
| type: DATA_SOURCE | |
| id: 5ec609320149d45eeb9dbec8 | //数据源ID |
| database.name.pattern: location | //源库名称正则 |
| table.name.pattern: lxy_test2 | //集合名正则 |
| retrieve.all.records: 'false' | //是否从头读取oplog,如果该值为true, 则不用设置offset.timestamp和offset.number; |
| offset.timestamp: '-1' | //时间戳偏移量,从该值开始读取。-1表示从当前时间开始读取(当前版本未启用) |
| offset.number: '0' | //偏移值(当前版本未启用) |
6.5 mysql-pattern-query-input(MySQL-模式匹配-读取组件)
通过正则模式匹配MySQL数据源的数据库/表的数据(分库分表合并的场景)。
6.6 fetch-http-input(HTTP(GEPS)-多表-读取组件)
GEPS产品数据通过HTTP方式读取多个业务表(表名list需要给出)。
这是一个输入组件,主要功能是抓取数据源为HTTP的数据,目前支持GEPS全量数据的获取,支持分页查询。
| 信息名称 | 描述 |
|---|---|
| 数据来源名称 | 下拉菜单格式,选择内容为在数据源管理中已配置完成的HTTP数据源 |
| 数据表/模型 | 所选择的HTTP数据源中需要读取的表名 |
| 页码 | HTTP数据的页码数,须不超过数据量 |
| 分页条数 | HTTP数据的分页条数,须不超过数据量 |
fetch-http-input组件高级模式规则:
| reference: | |
| type: DATA_SOURCE | |
| id: 5ecb95ccc576b81719e31252 | //数据源ID |
| page.size: '200' | //分页条数 |
| page.index: '0' | //页码 |
| table.name: TE_AF_CARRYOVER | //表名 |
| access.token: oRUDr4u6+QWbrbksXWm/cd2G5eBooGz5aN8 kYblGxlJXN6Q7fZadDzD2S28YvmgyVWIbtb jnhK5iYH38DjDK2U95HoawVCaLZAAPoQJRqXU= | //访问令牌 |
6.7 kafka-consume-input(Kafka-单主题-读取组件)
读取Kafka单个topic的数据。
6.8 aecore-http-input(HTTP(AECORE)-单表-读取组件)
通过HTTP请求获取AECORE的资源API里面的单个表模型的数据。
6.9 fetch-construction-http-input( HTTP(GDC)-视图API单表-读取组件)
通过HTTP请求获取GDC的视图API里面的单个表模型的数据。
6.10 jdbc-query-output(数据中台-单表-写入组件)
数据写入到数据中台的某个域下面的单个模型。
这是一个输出组件,功能为将数据写入到指定的数据表/模型中,对应方式为查询和抓取的input组件(目前支持mongo-query-input、jdbc-query-input、fetch-http-input,共三个组件)。
根据需求不同,数据目标的类型也会不同,目前分为JDBC类和数据中台(GDC)类,在新建任务中根据所选择的流程模板,jdbc-query-output组件会读取对应数据目标类型的token,并在简单模式的“数据目标名称”的下拉菜单中对应显示。
| 信息名称 | 描述 |
|---|---|
| 数据目标名称 | 下拉菜单格式,内容为根据在新增任务中的流程选择显示数据目标,JDCB类或GDC类 |
| 数据表/模型 | JDCB类中的数据表名称,GDC类中的数据模型名称 |
jdbc-query-output组件高级模式规则:
JDBC类:
| reference: | |
| type: DATA_SOURCE | |
| id: 5ebd367d78020e67021fb1c8 | //数据目标ID |
| table.name: testab2 | //数据表/模型名称 |
GDC类:
| password: Dat@h0b | //GDC账号密码 |
| table.name: app_pg_id_test_02 | //数据目标ID |
| url: jdbc:postgresql://pgm-2ze7x8327r281606117910.pg.rds.aliyuncs.com:1433/ app_zqz123456?useUnicode=true&allowMultiQueries=true&characterEncoding=UTF8 | //数据目标URL |
| username:datahub | //GDC用户账号 |
6.11 jdbc-standard-output(JDBC-单表-同步组件)
数据同步到JDBC类数据源的单个模型(CDC模式)。
这是一个输出组件,与jdbc-query-output组件格式相似,不同点是通过SQL日志的方式获取的变动数据写入数据库,对应Binlog或Oplog方式的input组件(mysql-binlog-input、mongo-query-oplog-input),可以执行增、删、改操作。
| 信息名称 | 描述 |
|---|---|
| 数据目标名称 | 下拉菜单格式,内容为根据在新增任务中的流程选择显示数据目标,JDCB类或GDC类 |
| 数据表/模型 | JDCB类中的数据表名称,GDC类中的数据模型名称 |
jdbc-standard-output组件高级模式规则:
JDBC类:
| reference: | |
| type: DATA_SOURCE | |
| id: 5ebd367d78020e67021fb1c8 | //数据目标ID |
| table.name: testab2 | //数据表/模型名称 |
GDC类:
| password: Dat@h0b | //GDC账号密码 |
| table.name: app_pg_id_test_02 | //数据目标ID |
| url: jdbc:postgresql://pgm-2ze7x8327r281606117910.pg.rds.aliyuncs.com:1433/ app_zqz123456?useUnicode=true&allowMultiQueries=true&characterEncoding=UTF8 | //数据目标URL |
| username:datahub | //GDC用户账号 |
6.12 jdbc-trunc-table-query-output(JDBC-单表-写入组件)
数据写入到JDBC类的的单个表模型。
6.13 jdbc-standard-output(unsorted)(JDBC-单表-同步组件(无序))
数据无序(多线程)同步到JDBC类数据源的单个模型(CDC模式)。
6.14 geps-output(JDBC-批量-写入组件)
数据批量写入到JDBC的某个域的多个表模型(GEPS场景,数据表模型根据名称自动映射)。
6.15 hdfs-output(HDFS-单路径-写入组件)
数据写入到HDFS的单个路径下。
6.16 jslt-transform(字段转换组件)
字段的列名的转换,字段类型的转换等处理。
这是一个转换组件,可以根据指定的JOLT规范对原JSON内容进行转换。
如Fig5简单模式中,左侧为数据目标中数据表/模型的字段名称,右侧为数据来源中数据表的查询字段以及转换公式。
transform组件带有两个默认函数,分别是retainUpstreamKeys函数和keyToLowercase函数。
retainUpstreamKeys函数在此处的作用为保留数据来源中的所有字段,如果数据来源与数据目标的表结构完全相同,则可以不对transform组件进行其他配置,如果表结构不同,仅需补充配置即可,而不用将名称和格式一致的组件再次进行填写配置。
keyToLowercase函数在此处的作用为将数据来源表结构中所有字段名称变为小写,以更好面对生产环境中的需要。
两函数的书写格式如下所示,其他书写方式详见附表。
| "retainUpstreamKeys":match-keys(".."), |
| "keyToLowercase": match-keys("..") |
| 信息名称 | 描述 | 范例 |
|---|---|---|
| 转换输出 | 输出组件对应的数据目标中数据表/模型需要写入的字段名称 | "id" 默认函数填写方式: "retainUpstreamKeys""keyToLowercase" |
| 转换公式 | 输入组件对应的数据来源中需要读取的的字段名称以及转换公式 | .id 默认函数填写方式:match-keys("..") match-keys("..") 其他自定义函数详见附录 |
6.17 json-split-transform(JSON拆分组件)
将JSON数组拆分成单个对象。
# 7 任务流程配置

Fig 6为任务流程配置例图,其中①修改任务名称,②修改描述名称,③输入组件,④转换组件,⑤输出组件,⑥调度时间设置,⑦切换简单模式和高级模式切换,⑧任务组件管理,⑨日志查询,⑩数据监控。
⑪区域是在任务提交成功后出现的部分,⑫刷新,刷新任务的当前状态,⑬启动/暂停,⑭更多,任务配置的其他功能,目前包括规则设置,详见7.4任务规则设置。
7.1 调度设置
任务调度是通过设置调度的执行时间来按周期执行任务流程。
调度目前分为日、周、月和间隔四种模式。
日模式可设置每天任务调度执行的时分秒;
周模式可设置每周任务调度执行的周几以及周几的时分秒;
月模式可设置每月任务调度执行的某月的几号以及某月的几号的时分秒;
间隔模式可设置每次任务调度执行的间隔时间,包含分钟和秒两种间隔时长,并且当任务启动时,会立即执行一次,下一次会等到间隔时间到了之后再执行。
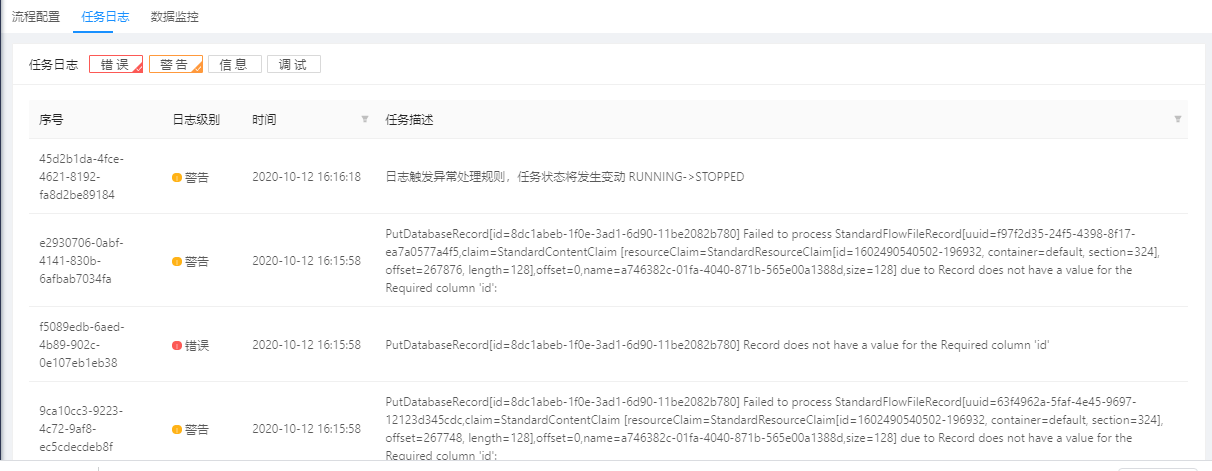
7.2 任务日志
用户可以通过查询日志来了解任务运行过程中的状态,每一个日志生成时都携有序号、日志级别、时间和任务描述四类信息,我们可以根据其中的日志级别、时间和任务描述对日志进行筛选查询。
当前的日志级别包括调试、信息、警告和错误四类。
7.3 流程模板介绍
在5.3节中介绍了数据集成的流程模板,并在第六章中介绍了八类组件,下文将会根据任务功能和组件搭配的角度对模板进行讲解。
7.3.1 单表-JDBC-导入到数据中台(single-JDBC-GDC)
涉及组件:
jdbc-query-input
jslt-transform
jdbc-query-output
支持数据由从JDBC类的数据源的单个表导入到数据中台的单个模型。
7.3.2 单表-MongoDB-导入到数据中台(single-MongoDB-GDC)
涉及组件:
mongo-query-input
jslt-transform
jdbc-query-output
支持数据由从MongoDB的数据源的单个表导入到数据中台的单个模型。
7.3.3 单表-MySQLBinlog-同步到数据中台(single-MySQLBinlog-GDC)
涉及组件:
mysql-binlog-input
jdbc-standard-output
支持CDC模式的数据接入方式,通过正则模式匹配MySQL的数据库/表同步到数据中台的单个模型。
7.3.4 单表-MongoOplog-同步到数据中台(single-MongoOplog-GDC)
涉及组件:
mongo-query-oplog-input
jslt-transform
jdbc-standard-output
支持CDC模式的数据接入方式,通过正则模式匹配MongoDB的数据库/集合同步到数据中台的单个模型。
7.3.5 模式匹配-MySQL-合并到数据中台(pattern-MySQL-GDC)
涉及组件:
mysql-pattern-query-input
jslt-transform
jdbc-query-output
支持通过正则模式匹配MySQL的数据库/表,合并成一个表,写入到数据中台的单个模型中。(备注:必须要保证正则模式匹配的多个表的表结构一致。)
7.3.6 模式匹配-MySQLBinlog-推送到数据中台Kafka(pattern-MySQLBinlog-Kafka(GDC))
涉及组件:
mysql-binlog-input
cdc-sys-kafka-output
支持CDC模式的数据接入方式,通过正则模式匹配MySQL的数据库/表同步到数据中台的Kafka消息队列。
7.3.7 模式匹配-MongoOplog-推送到数据中台Kafka(pattern-MongoOplog-Kafka(GDC))
涉及组件:
mongo-query-oplog-input
cdc-sys-kafka-output
支持CDC模式的数据接入方式,通过正则模式匹配MongoDB的数据库/集合同步到数据中台的Kafka消息队列。
7.3.8 单表-HTTP(AECORE)-导入到数据中台(single-HTTP(AECORE)-GDC)
涉及组件:
aecore-http-input
jslt-transform
json-split-transform
jdbc-query-output
支持通过HTTP请求获取AECORE的单个表数据,写入到数据中台的单个模型中。
7.3.9 单表-JDBC-导入到JDBC(single-JDBC-JDBC)
涉及组件:
jdbc-query-input
jslt-transform
jdbc-trunc-table-query-output
支持数据由从JDBC类的数据源的单个表导入到JDBC类的的单个表。
7.3.10 单表-MongoDB-导入到JDBC(single-MongoDB-JDBC)
涉及组件:
mongo-query-input
jslt-transform
jdbc-trunc-table-query-output
支持数据由从MongoDB的数据源的单个表导入到JDBC类的的单个表。
7.3.11 单表-MySQLBinlog-同步到JDBC(single-MySQLBinlog-JDBC)
涉及组件:
mysql-binlog-input
jdbc-standard-output
支持CDC模式的数据接入方式,通过正则模式匹配MySQL的数据库/表同步到JDBC类数据源的单个模型。
7.3.12 单表-MongoOplog-同步到JDBC(single-MongoOplog-JDBC)
涉及组件:
mongo-query-oplog-input
jslt-transform
jdbc-standard-output
支持CDC模式的数据接入方式,通过正则模式匹配MongoDB的数据库/集合同步到JDBC类数据源的单个模型。
7.3.13 单表-MongoOplog-同步到JDBC(无序)(single-MongoOplog-JDBC(unsorted))
涉及组件:
mongo-query-oplog-input
jslt-transform
jdbc-standard-output(unsorted)
支持CDC模式的数据接入方式,通过正则模式匹配MongoDB的数据库/集合同步到JDBC类数据源的单个模型。备注:这个是无序且多线程写入,提升了效率。
7.3.14 单表-MySQLBinlog-同步到JDBC(无序)(single-MySQLBinlog-JDBC(unsorted))
涉及组件:
mysql-binlog-input
jslt-transform
jdbc-standard-output(unsorted)
支持CDC模式的数据接入方式,通过正则模式匹配MySQL的数据库/集合同步到JDBC类数据源的单个模型。备注这个是无序且多线程写入,提升了效率。
7.3.15 模式匹配-MySQL-合并到JDBC(pattern-MySQL-JDBC)
涉及组件:
mysql-pattern-query-input
jslt-transform
jdbc-trunc-table-query-output
支持通过正则模式匹配MySQL的数据库/表,合并成一个表,写入到JDBC的单个模型中。(备注:必须要保证正则模式匹配的多个表的表结构一致。)
7.3.16 单主题-Kafka-导入到HDFS(single-HTTP(GDCview)-GDC)
涉及组件:
kafka-consume-input
jslt-transform
hdfs-output
支持读取Kafka单个topic的数据,写入到HDFS的单个路径下。
7.4 任务规则设置
任务规则设置功能支持用户为任务配置自动停止或者暂停的规则。目前支持选择日志内容中需要处理的日志等级,并设置需要进行操作的任务。
此外,在触发的任务规则设置时,也支持向用户发送与订阅内容对应的邮件,确保用户可以知道任务的状态变更。任务操作包括不处理、暂停和停止。

7.5 数据监控
数据监控功能是通过数据来源与数据目标间的的数据比对,从而确保数据在导入和同步过程中的正确性。
数据监控主要从以下两个角度对任务数据进行比对,一是通过数据来源的入库时间字段与导入(同步)数据目标的对应时间类型字段进行比对,统计规定时间范围内两个数据源的数据总条数是否一致,从而达成验证效果,即总数验证;
二是通过两数据源键码比对的形式,定时抽取周期内导入(同步)的数据,并在一定时间后比对数据目标的指定字段是否一致,从而达成验证效果,即抽样验证。
7.5.1 总数验证
总数验证方式需要配置如下内容:对比模式、入库时间和过滤条件,对于入库时间字段有依赖,其中对比模式分为全量模式、增量模式和智能模式。

全量模式,在比对过程中的时间范围只设时间最大值,即每一次比对都将核实数据来源和数据目标中当时的所有数据条数是否相同,因为数据的导入和同步是存在延迟的,所以该模式设置了六小时(整时,即00:00,06:00,12:00……)的时差来面对生产环境中存在的延迟状况,因此单次全量导入时间需要超过六小时才可以完成导入的任务流程不适用该模式。
全量模式示意图见Fig 10,其中0H代表验证开始(整时),相同颜色代表一组需要全量验证的时间段和验证执行的时间,每一小时更新一次需要全量验证的时间段,在六小时后对数据目标中需要时间段对应的数据进行count计数,并与数据来源进行验证。

增量模式,在比对过程中有明确的时间范围(整时,一小时,即00:00,01:00,02:00……),即每一次比对都将核实数据来源和数据目标中近一小时导入(同步)的数据条数是否相同,因为数据的导入和同步是存在延迟的,所以该模式设置了一小时的时差来面对生产环境中存在的延迟状况。需要注意,如果数据来源的当地时间与数据集成执行引擎的当地时间存在时差,或数据来源服务器和数据集成执行引擎的误差时间较大(超过2小时)时,不建议使用增量模式。
增量模式示意图见Fig 11,其中0H代表验证开始(整时),相同颜色代表一组需要增量验证的时间段和验证执行的时间,每一小时更新一次需要增量验证的时间段,在一小时后对数据目标中需要时间段对应的数据进行count计数,并与数据来源进行验证。

智能模式,全量模式与增量模式的结合,在启动验证时,第一次验证的模式是全量模式,随后验证的模式改为增量模式,推荐选择智能模式。
智能模式示意图见Fig 12,其中第一次的全量校验与之后每次的增量校验的规则与上文中所讲解的一致。

7.5.2 抽样验证
抽样验证方式需要配置如下内容:抽样条数、主键字段和比对字段。
在实际生产环境中,可能会出现联合主键的情况出现,所以主键字段是支持多条填写的,比对字段也支持多条填写,以应对需要验证多字段的情况出现。
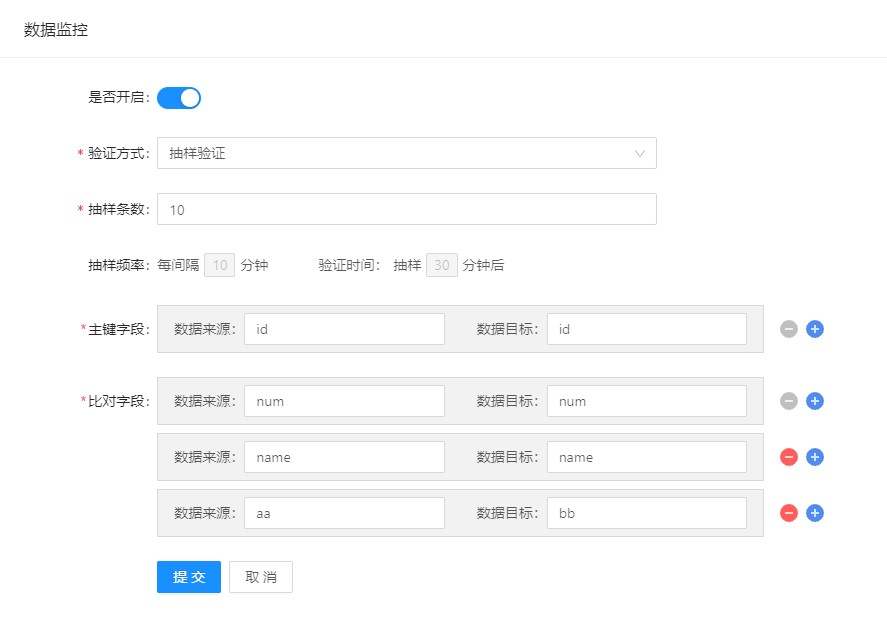
抽样验证的抽样频率为10min/次(整十分钟,如00:10、12:30…),在30min后对数据进行比对。
抽样验证的示意图见Fig 12,其中0min代表验证开始(整十分钟),相同颜色代表一组需要抽样比对的时间段和比对执行的时间,每10分钟进行一次抽样,在30分钟后跟据抽样数据的主键值在数据目标中进行查找,并根据数据来源与数据目标中抽样数据的比对字段的值进行验证。

# 附表
表1 自定义函数表
| 函数名 | 描述 | 原始值 | 变型值 | 备注 |
|---|---|---|---|---|
as-long | 把原始值变为 long 类型 | as-long("11111111111111111") | =11111111111111111 | |
| camelcase | 把 snake case 字符串变形为 camel case | camelcase("user_name") | ="UserName" | |
| snakecase | 把 camel case 字符变形为 snake case | snakecase("UserName") | ="user_name" | |
| substr | 截取字符串,按照 Java String.subString 暴露 1/2 个参数 | substr("abc", … | ="a" | |
| parseTime | 从 时间字符串(如2020-04-24 15:31:47.085)转换到 long型时间戳parseTime(String time, String format, String timeZone) | parseTime("2020-04-24 23:17:25.348","yyyy-MM-dd HH:mm:ss.SSS", "Asia/Shanghai") | =1587741445348 | 参数说明: format:如果不填,默认取值“yyyy-MM-dd HH:mm:ss”; 取值包括但不限于: yyyy-MM-dd'T'HH:mm:ss'Z' EEE MMM dd HH:mm:ss Z yyyy yyyy-MM-dd HH:mm:ss.SSSSSS yyyy-MM-dd HH:mm:ss.S yyyy-MM-dd HH:mm:ss yyyy-MM-dd HH:mm:ss.SSS yyyy-MM-dd timeZone:时区参数如果不填,取系统默认值 https://blog.csdn.net/micro8530/article/details/106783334/ 以下常规类型支持自动识别类型: yyyy-MM-dd HH:mm:ss.SSSSSS yyyy-MM-dd HH:mm:ss.S yyyy-MM-dd HH:mm:ss yyyy-MM-dd HH:mm:ss.SSS yyyy-MM-dd 像这种特殊类型,需指定设置: yyyy-MM-dd'T'HH:mm:ss'Z' EEE MMM dd HH:mm:ss Z yyyy |
| formatTime | 从时间戳long(毫秒数)转化成 格式化后的字符串(2020-04-24 15:31:47.085)formatTime(long timestamp, String format, String timeZone) | formatTime(1587741445348, "yyyy-MM-dd HH:mm:ss.SSS", "Asia/Shanghai") | ="2020-04-24 23:17:25.348" | 参数说明: format:如果不填,默认取值 yyyy-MM-dd HH:mm:ss”; timeZone:时区参数如果不填,取系统默认值 |
| getCurrentTime | 获取当前时间,返回字符型 | getCurrentTime(“format”, “timeZone”) getCurrentTime() getCurrentTime("","GMT+00:00") | =“2020-04-24 23:17:25.348000” | 参数说明: format: 返回的时间格式化参数,默认值为yyyy-MM-dd HH:mm:ss.SSSSSS timeZone: 时区参数,默认值为东8区(GMT+08:00) 若参数不填或为空则取默认值 |
| set-def | 当值为空的的时候,设置字段默认值 | set-def(.osType, 10086) | 10086 | 当字段osType值为空的时候,取值 |
| match-keys | 匹配字段key值,返回boolean类型 | match-keys("create_.*",".*Long") | true 或 false | 支持字段名匹配,支持正则表达式,常用正则表达式总结: .*. : 表示全部 .*time: key依time结尾 time.* : key依time开始 .*time.* : key包含time字符 id: 表示key为id |
| is-match | 指定key值判断是否满足匹配规则,返回boolean类型 | is-match($key, ".time. ") | true 或 false | is-match($key, ".time. ") 第一个参数是要匹配的字段,后面为匹配规则,支持可变参数如:is-match($key, ".*time.* ","name",,"id") |
| to-boolean | 根据入参值返回 true或false | to-boolean(.bitKey) | true 或 false | Everything is considered to be true, except null, [], {}, "", false, and 0 |
| del-prefix | 删除前缀,并返回删除前缀后的小写形式 | del-prefix("F_ID") | id | 如果字符串中间没有“_”,则会返回原4字符串的小写化 如: AAA → aaa; F_ID → id |
| lowercase | 大写转小写 | lowercase("AAAAA") | aaaaa | jslt 原生函数 |
| replaceAll | 利用String.replaceAll进行替换 | replaceAll("aaabbbccc","bbb","ddd") | aaadddccc | 底层利用 String.replaceAll(regex, replacement)进行处理 |
| booleanToInt | boolean 类型转int | booleanToInt(.bitKey) | true→ 1;false → 0 ;null → null |
表2 设置key的处理方式
| (一)删除前缀key的小写化(如果包含这两种方式,先处理keyToLowercase 后keyToDelPrefix) |
|---|
| spec: { "keyToDelPrefix": match-keys(".*time"), "keyToLowercase": match-keys(".*.") } |
| (二)保留上游输入的键值对(key-value) |
| spec: { "retainUpstreamKeys": match-keys(".*.") } |
| (三)新增删除key函数 |
| spec: { "removeKeys": match-keys(".*time") } |
| (四)新增重命名key |
| spec: { "renameKeys": renameKeys("newKey1:oldKey1","newKey2:oldKey2","newKey3:oldKey3") } |
| (五)新增设置 FlowFile 属性值 |
| spec: { "subAttribute": subAttribute("p_id01;cdc.database.name;1","p_id02;cdc.database.name;1"), // 输出字符型 "subAttributeToNum": subAttribute("p_id01;cdc.database.name;1","p_id02;cdc.database.name;1") // 结果转化为长整型 } //在字符串"p_id01;cdc.database.name;1"中,"p_id01"表示把转化后对值放到p_id01这个字段上; //"cdc.database.name":表示flowfile中的属性值; //"1":表示cdc.database.name属性值从1开始substring |
← 数据资源与控制台说明文档 服务开通说明 →