# 数据资源与控制台说明文档
# 1 模块及功能概述
数据资源模块的核心是通过对不同领域的资源进行建模,并与资源的提供者进行绑定,通过整合各种数据类型,建设一个统一的数据服务平台,为开发者提供的工具,数据和接口服务,完成数据类应用开发。
# 2 应用场景
# 3 快速指南
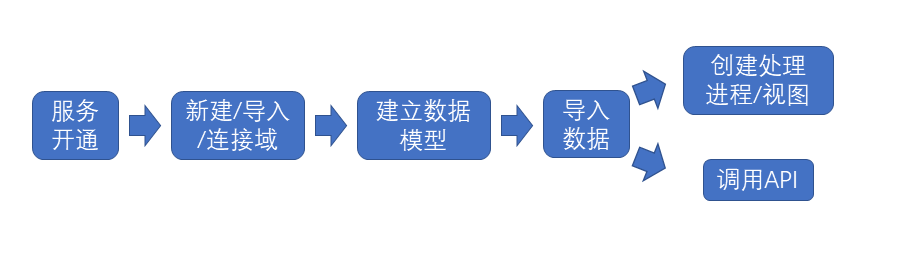
# 4 名词解释
领域(Domain):领域是对一类业务范畴内的知识,术语和关系的抽象,由一个业务范畴内密切相关的实体和他们之间的关系组成。Domain 内的数据模型原则上独立存储,但可以互相关联和引用。Domain 是平面结构,一个Domain不应包含其他Domain,Domain 之间的包含关系通过类型引用实现。典型的业务领域如项目管理,安全管理,物料管理,甲方监管,物联网等。领域是模型的容器,例如地铁域包含线路、站点等模型,而项目、租户等模型则在项目信息域里。
资源模型(Model):一个资源模型代表一个可供访问的数据资源,如劳务人员,安全巡检记录,BIM模型等,PDC 采用动态建模,开发者可通过模型设计器,在线设计和修改资源模型。
视图(View):视图代表对资源模型的不同服务形态,通过引入视图,对同样的资源模型,开发者可根据需要组织不同 API 形式。 视图是由视图模板(View Template)生成的,是根据模型的关联关系动态创建关联树。
# 5 控制台
5.1 域管理
通过资源管理,可以查看到与用户相关的域,包括创建的域、参与的域、可见的域和已删除的域,并可以对域进行相关操作。
如下图所示,①域的筛选列表,可将域分为全部、创建的(当前用户创建的域)、参与的(作为域成员,而非创建者和所有者参与的域)、可见的域(看到的其他用户创建的公共域和共享域)、导入、远程和已删除的域并结合排序规则进行查看。
②根据①的筛选条件显示相关域的信息。
③在②中,每一个卡片代表一个域,对于创建的域,可以进行配置、删除操作,还可以查看对应域的数据资源信息,并进行数据服务(开发中)、分析(开发中)和运维配置(开发中)操作。
④新建域、远程连接域(开发中)和导入公共域(开发中)。

5.1.1 新建域
新建域时需要填写的信息及说明如下表所示。
| 信息类别 | 详细信息 | 内容 |
|---|---|---|
| 基本信息 | 域ID | 必填,2~40个字符,小写字母开头,小写字母与数字、下划线组合 |
| 中文名 | 必填,2~64个字符 | |
| 描述 | 256个字符以内 | |
| 详细信息 | 环境 | 开发环境/生产环境 |
| 资源可见度 | 私有/共享/公共 | |
| 规范 | 自由建模/强制数据关联,是否允许数据导出 | |
| 自定义属性 | 属性名、属性值,可不填或填写多个 | |
| 绑定资源引擎实例 | 可用资源引擎 | 详见5.2服务开通 |
| 成员信息 | 成员名称 | 需要参与到本域的用户名 |
| 角色 | 域所有者、域管理员、开发者、运营者、访客,权限详见附表-角色权限 |
注:资源可见度的三种类型具体含义分别为:
- 私有:仅域所有者可见,其他人无法查看该域;
- 共享:设置域为共享时,除域所有者外其他人可查看该域的元数据信息,但无法预览数据;
- 公共:所有人均可看到该公共域的元数据信息及预览数据。
5.1.2 域操作
在域列表中我们可以对域进行操作,如5.1中图所示,⑤查看该域的数据资源;⑥数据服务(未实现);⑦开始分析(未实现);⑧开始运维(未实现);⑨该域的配置配置;⑩删除该域。
配置域
通过配置域,可对域的描述、业务信息(开发环境、生产环境)、安全信息、自定义属性、成员、引擎实例进行管理。
删除域
权限为域所有者的用户可以执行删除对应域的操作,删除后的域可以在域列表的“已删除”中查看并恢复(时限为七天内)。有应用绑定的域不可以删除。
5.2 服务开通
对于每个域,都需要开通对应所需的引擎服务,才能保证域的正常运行。目前数据资源所支持的引擎如下表所示。
| 序号 | 引擎名称 | 引擎描述 |
|---|---|---|
| 1 | GreenplumEngine | GP数据引擎 |
| 2 | TaskAnalysisEngine | TASK分析引擎(支持SQL数据离线分析) |
| 3 | Postgresql | PG数据引擎 |
| 4 | SQLAnalysisEngine | SQL分析引擎(支持SQL数据实时分析) |
| 5 | TimeSeries | TS数据引擎(时序数据处理) |
| 6 | FileStore | GDOC文件引擎 |
申请数据引擎需要点击对应引擎下的“申请开通”按键,需要填写的内容有等级(必填,标准级、专业级、企业级)和说明。
已经申请通过的引擎服务,点击“调整”,可更新引擎服务的配置内容。
5.3 数据授权
5.3.1 我的权限
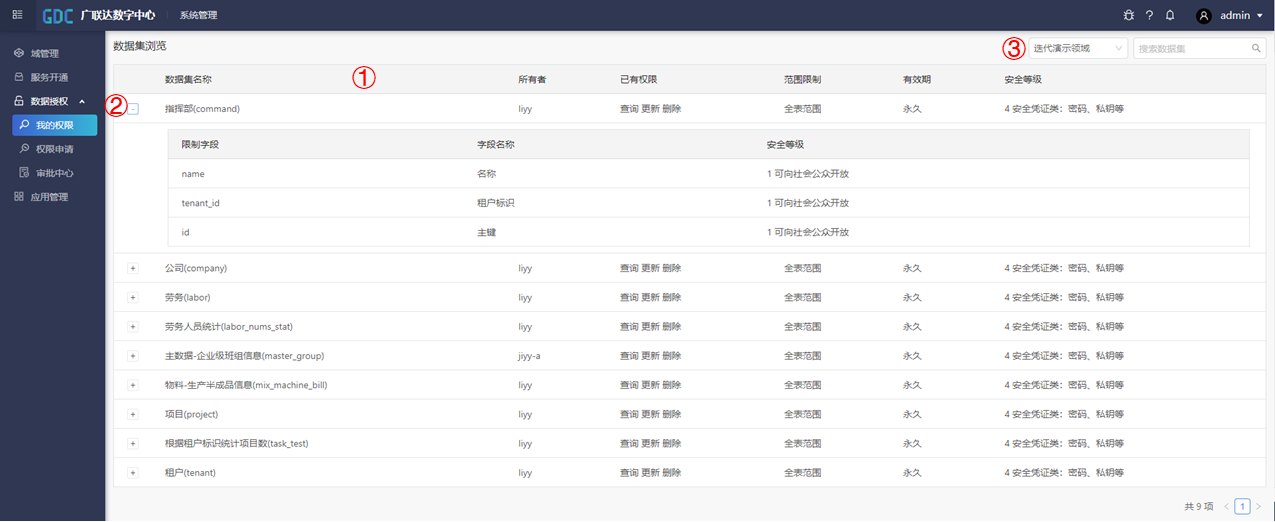
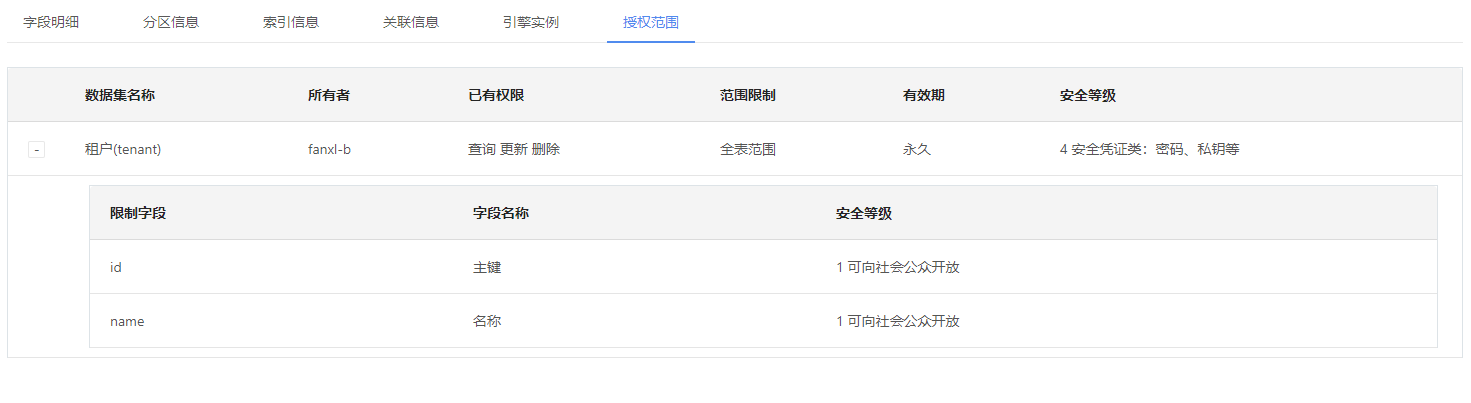
如下图所示,在我的权限中,根据①,可以选择查看到当前用户在所选域的数据资源的信息,包括数据资源名称、所有者、已有权限、查看的范围限制、有效期和安全等级。
按下②的“+”后,可查看到对应数据资源中的字段信息,包括限制字段、字段名称和安全等级。
③根据搜索内容,可以查看到某个域的对应数据资源。
5.3.2 权限申请
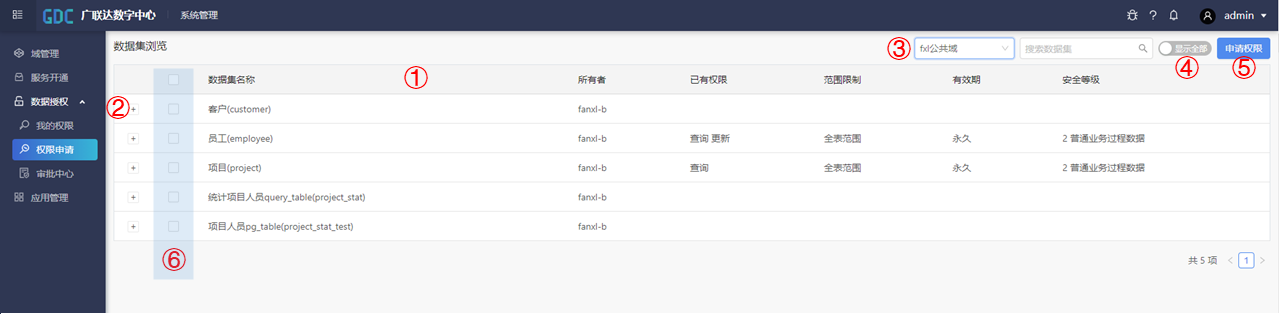
如下图所示,在权限申请中,与我的权限相似,①可以选择查看到当前用户在所选域的数据资源的信息,包括数据资源名称、所有者、已有权限、查看的范围限制、有效期和安全等级。
按下②后,可查看到对应数据资源中的字段信息,包括限制字段、字段名称和安全等级。
③根据搜索内容,可以查看到当前域的对应数据资源。
④显示全部/只显示未授权,显示当前域中的全部/已获得权限的数据资源。
⑤申请权限,对⑥中勾选的数据资源进行权限申请。
下图为数据资源申请界面
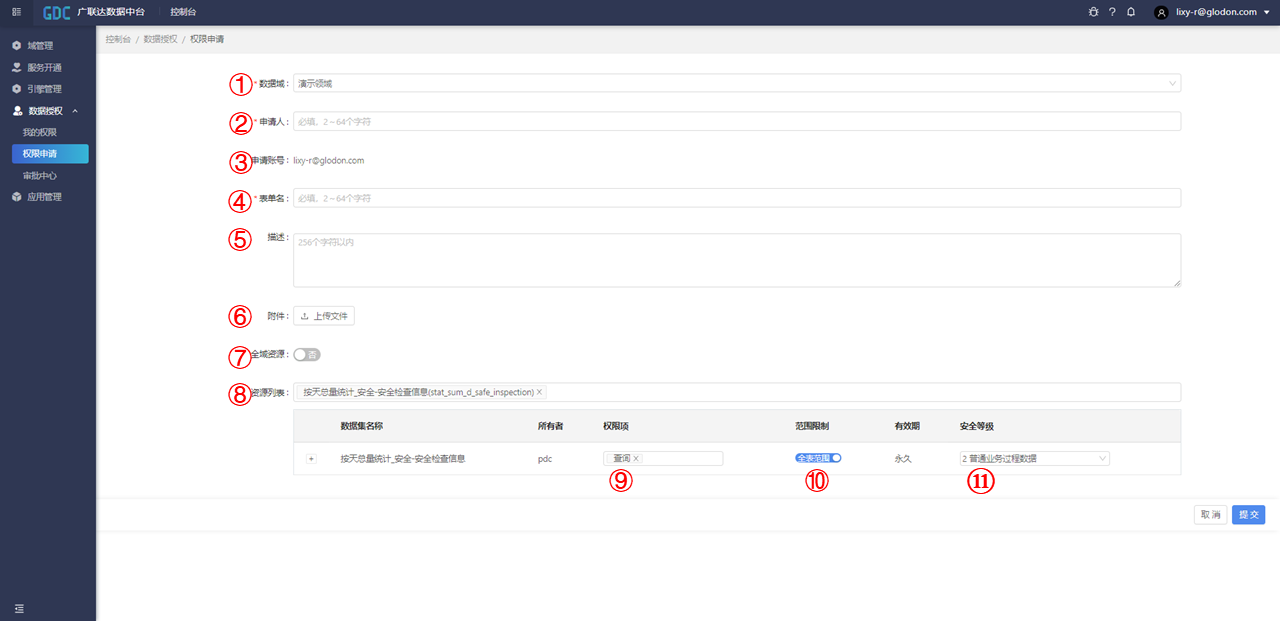
| 图中序号 | 申请信息 | 信息解释 |
|---|---|---|
| ① | 数据域 | 所申请数据资源的所属域 |
| ② | 申请人 | 申请人姓名 |
| ③ | 申请账号 | 提交申请的域账号 |
| ④ | 表单名 | 申请表单名称 |
| ⑤ | 描述 | 申请表单描述 |
| ⑥ | 附件 | 可上传申请所需附件 |
| ⑦ | 全域资源 | 是否开启全域资源,即可对全域内数据资源的权限进行申请 |
| ⑧ | 资源列表 | 填写申请权限涉及的数据资源 |
| ⑨ | 权限项 | 申请数据资源的权限内容(查询、更新和删除),非全域资源填写 |
| ⑩ | 范围限制 | 是否开启范围限制(全表范围/选择范围,详见6.4范围管理),非全域资源填写 |
| ⑪ | 安全等级 | 1可向社会公众开放、 2普通业务过程数据、 3身份和商业敏感:身份、财务等、 4安全凭证类:密码、私钥等 |
5.3.3 审批中心
在审批中心中,可查看到当前用户关于域和数据资源权限的所有审批流程信息。
审批中心主要分为三部分,包括我的申请、待我审批和我已审批。
三部分显示的相同信息类别包括申请单号、申请单名、申请时间、审批状态、数据域、资源列表、审批人和备注。不同点如下所示:
我的申请,即当前用户所提交的全部申请信息,并可进行“查看详情”操作,查看申请人在申请表单中所填写的内容(见5.3.2中表)。
待我审批,即查看其他用户对当前用户创建的域和数据资源权限申请的待处理信息,并可进行批准、拒绝和查看详情操作。
我已审批,即查看其他用户对当前用户创建的域和数据资源已处理的权限申请信息,并可进行“查看详情”操作。
5.4 应用管理
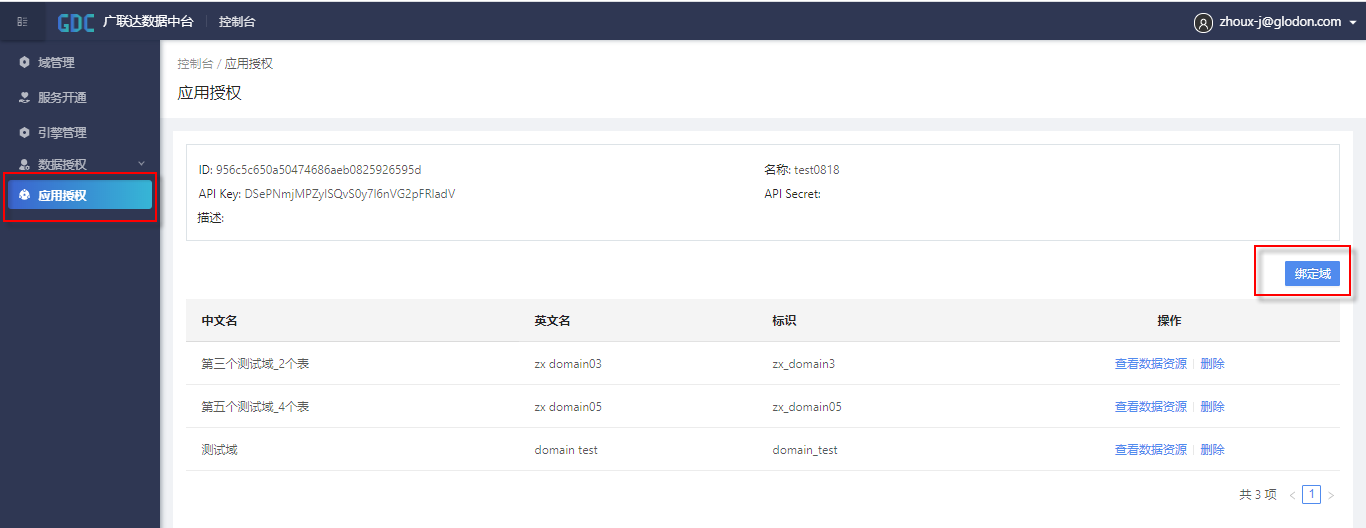
将当前用户的应用信息(AECORE)与拥有权限的域进行绑定,便于之后通过应用对域内的资源进行调用。选中某个应用,点击进入详情页后,添加绑定的域。绑定成功后,用户就可以使用在AECORE中获取的token对域内的资源进行查询、编辑、删除等操作,如下图所示。
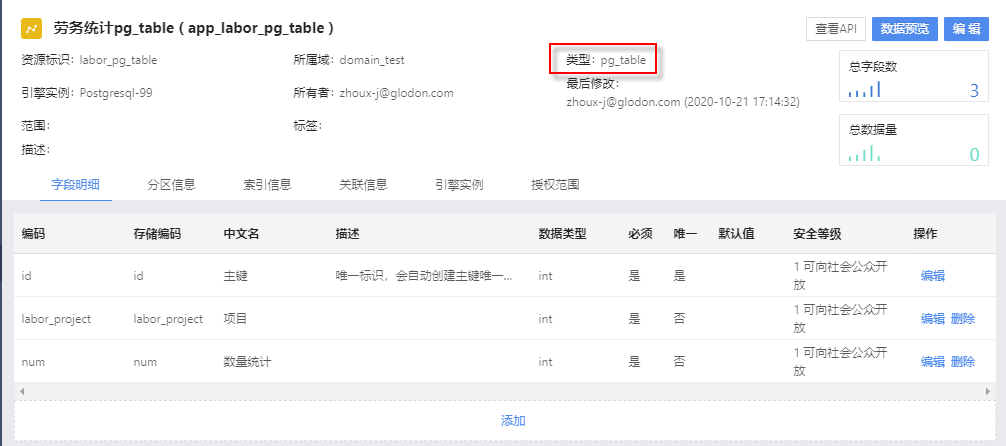
# 6 数据资源
6.1 导航栏
数据目录
数据探查
标签管理
范围管理
6.2 数据目录
数据目录是对域中的数据资源进行查看和操作的二级模块,如下图所示 。

①选择域,查看所选择的域。
②域中数据资源的信息。
③根据②中选择的数据资源,显示对应数据资源信息,包括数据资源名称、资源标识、所属域、类型、引擎实例、所有者、最后修改用户名称、最后修改时间、范围和标签信息,以及数据资源的总数据量和总字数段。
④当前数据资源的其他信息,包括字段信息、分区信息、索引信息、关联信息、引擎实例和范围授权。
⑤新建数据资源,新建方法包括新建数据表、新建文件集、导入文件和导入BIM模型。
⑥刷新。
⑦数据预览,显示当前数据资源的数据。
⑧编辑,可编辑当前数据资源基本信息,内容包括中文名、英文名、描述、范围和标签。
⑨数据关联,通过设置主、外键关联的形式,使数据资源之间产生关联关系。
⑩数据工厂,通过执行脚本的方法,对数据资源中的数据进行加工处理。
⑪数据服务,利用⑩的数据资源关联关系和5.4应用管理中的绑定API,向用户提供数据服务,服务包括数据资源中的数据查询以及数据资源的关系查询。
删除数据资源,在上图②中,数据资源根目录(域)下,可对当前域下的数据资源进行删除。
6.2.1 数据资源信息
在6.2中已经介绍过,数据资源信息主要分为两大类:基本信息和其他信息。
其中其他信息包括字段信息、分区信息、索引信息、关联信息、引擎实例和范围授权,在本节中,将对这几类信息进行详细介绍。
①字段信息:当前数据资源中字段的信息,包括字段ID、中文名、描述、数据类型、是否必须、是否唯一、默认值和安全等级(详见表5.3.2表中安全等级分级)。
此外还可以对字段进行添加、修改和删除操作,其中主键仅可进行修改操作。

②分区信息。
③索引信息:当前数据资源中的索引信息,包括索引名称、类型、是否唯一和索引字段,其中类型包括btree、hash、gin、gist、sp-gist、brin、rum、bloom、zombodb和bitmap;索引字段支持多字段升降序排列方式。

④关联信息:涉及当前数据资源的关联信息,包括主动关联和被动关联。显示的信息包括关联名字、表示、描述、类型和关系,其中关联类型默认为静态关联。
此外还可以对关联信息进行添加、修改和删除操作,且被动关联的关联信息不可进行修改。

关联信息还可以图形方式查看。

⑤引擎实例:当前数据资源的引擎实例信息。
⑥授权范围:可查看到当前登录状态下的用户在所选数据资源已获得的权限信息。
6.2.2 新建数据资源
当前版本数据资源模块支持的新建方法包括新建数据表、新建文件集、导入文件和导入BIM模型。
新建数据表
在新建数据表是,需要填写下表中的信息。其中资源类型为pg_query_table不需要填写类型相关信息
| 信息类型 | 信息名称 | 备注 |
|---|---|---|
| 基本信息 | 资源类型 | pg_query_table、 pg_table、 ts_table、 gp_table |
| 资源引擎实例 | Postgresql-15(pg_query_table、pg_table) TimsSeries-16(ts_table) GreenplumEngine(gp_table) | |
| 类型相关信息 | 资源ID | 必填,2~40个字符,小写字母开头,小写字母与数字下划线组合 |
| 中文名 | 必填,2~64个字符 | |
| 描述 | 256个字符以内 | |
| 标签 | 下拉菜单格式,可多选,详见6.3标签管理 | |
| 字段信息 | 添加/修改字段,包括字段ID、中文名、描述、数据类型、是否必须、是否唯一、默认值、安全等级 | |
| 是否分区 | 资源是否进行分区存储 | |
| 分区类型 | 下拉菜单格式,RANGE、LIST、HASH | |
| 分区字段 | 下拉菜单格式,根据上表的新增字段填写 | |
| 分区块 | 分区表明、默认、起点值、终点值、值列表、Hash分表数 | |
| 配置其他信息 | 索引信息配置 | 详见6.2.1数据资源信息③索引信息 |
新建文件集
| 信息类型 | 信息名称 | 备注 |
|---|---|---|
| 基本信息 | 资源类型 | general_file、 bim_model_file |
| 资源引擎实例 | FileStore-17 | |
| 类型相关信息 | 资源ID | 必填,2~40个字符,小写字母开头,小写字母与数字下划线组合 |
| 中文名 | 必填,2~64个字符 | |
| 描述 | 256个字符以内 | |
| 标签 | 下拉菜单格式,可多选,详见6.3标签管理 | |
| 字段信息 | 添加/修改字段,包括字段ID、中文名、描述、数据类型、是否必须、是否唯一、默认值、安全等级,文件资源默认字段详见附表-文件字段信息表 | |
| 配置其他信息 | 索引信息配置 | 详见6.2.1数据资源信息③索引信息 |
批量建模
该功能可以将数据库已有的模型,批量的在数据资源加载出来,以便可以快速将已有模型在数据资源加载。

如下图所示,批量建模可以通过数据存储引擎和文件的形式实现。

资源类型,包括pg_query_table、pg_table、ts_table和gp_table;
资源存储引擎,(需要用户自行建立数据分析引擎);
模型定义来源,数据存储引擎和文件。
当选择文件时,需要上传对应的定义文件(excel)。该excel至少3个Sheet,Sheet说明如下表所示,其余信息见附表。
| Sheet 说明 | |
|---|---|
| Sheet 1 | 说明页 (本页),不要做任何修改 |
| Sheet 2 | conf,资源类型及数据类型配置页,不要做任何修改 |
| Sheet 3~N | 每一页一个模型定义 |
当选择数据存储引擎时,如图数据所示,可以直接根据该数据存储引擎中的字段信息进行反向建模。

导入文件
通过导入文件,可以将文件形式的数据导入到文件数据资源中。
在导入设置过程中,基本信息填写情况如下表所示。
| 信息类别 | 信息名称 | 备注 |
|---|---|---|
| 基本信息 | 资源类型 | 必填,默认general_file |
| 资源引擎实例 | 必填,例如FileStore-17 | |
| 目标数据资源 | 导入文件的目标数据资源 | |
| 文件信息 | 选择文件 | 选择文件进行上传 |
| 文件描述数据 | 详见文件字段信息表 |
导入BIM模型
通过BIM模型,可以将BIM文件导入到文件数据资源中。
6.2.3 数据关联
通过数据关联,可以使数据资源间的关系类似于数据库中“一对多”的关联关系。如下图所示,此时正在创建关联,其中需要填写的信息包括关联名字(必填)、编码(必填)、描述、源资源、源资源属性、目标资源和目标资源属性,其中目标资源属性只支持ID。
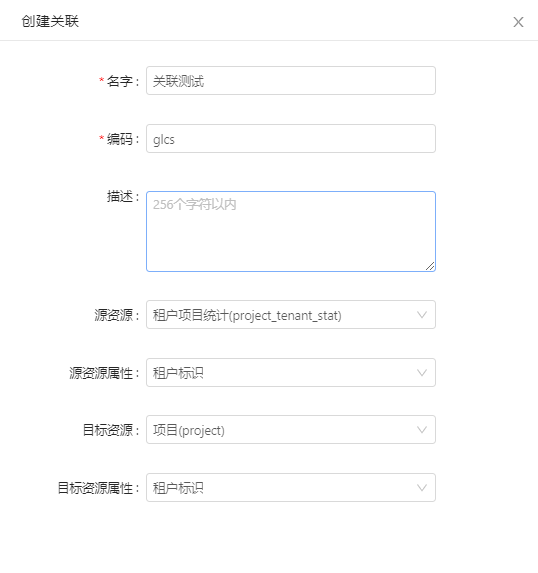
其中源资源代表的是“一对多”中的“多”,而目标资源代表“一”。
6.2.4 数据工厂
在数据工厂中,可以用SQL语言对数据中台的数据进行加工处理。数据工厂任务分为两类,一类是实时任务,一类是离线任务。在数据工厂模块中,还可以查看到当前域在之前已经配置好的处理进程,并对其进行修改和删除。
实时任务,需要用户先创建一个query_table类的数据资源,这个是一个数据查询模型,里面不会存放数据。对应再创建一个Query类的实时数据工厂任务,将目标数据资源指向之前创建的query_table。里面的数据可以通过API进行查看。
离线任务,需要先创建一个普通的数据资源如pg_table,再创建一个Task类的数据工厂任务,离线任务还需要设置一个cron的调度,工厂任务会定时执行。Task类的数据工厂任务执行的结果会写入到数据资源里面,在数据资源的“数据预览”就可以直接看到数据。
点击创建处理进程,即可新建处理进程。如下图,是一个已经创建好的处理进程。

可以看到,当前版本创建新的处理进程需要填写以下信息:
资源类型,包括Query类和Task类,目前Query类支持创建pg_sql进程,Task类支持创建cron_task,其中pg_sql对应pg_query_table类型的数据资源,执行后可根据数据服务的API进行查看,cron_task对应pg_table类型的数据资源,执行后可到对应的数据资源中进行查看(6.2.2新建数据);
资源引擎实例,在5.2服务开通中申请的数据分析引擎,目前已SQL类为主,pg_sql进程对应SQLAnalysisEngine引擎,cron_task对应TaskAnalysisEngine引擎;
目标资源,即数据处理的结果写入的数据资源;
名字,处理进程名称,必填,2~64个字符;
编码,处理进程编码,必填2~40个字符,小写字母开头,小写字母与数字、下划线组合;
描述,处理进程的描述;
执行脚本,需要执行的SQL语句;
CRON表达式,当处理进程为cron_task时必填,遵循CRON表达式规则,以此控制进程的调度,例如“0 0 0 1/1 * ?”,即为从每月1日开始,每天执行一次。
在创建数据工厂任务之前,需先创建一个pg_table数据表,存放有实际的业务明细数据,之后再创建任务对该数据表的数据进行加工处理。下面分别是实时任务和离线任务的创建过程:
- 实时任务
步骤一:创建query_table查询模型。该查询模型的字段为需要统计的指标。
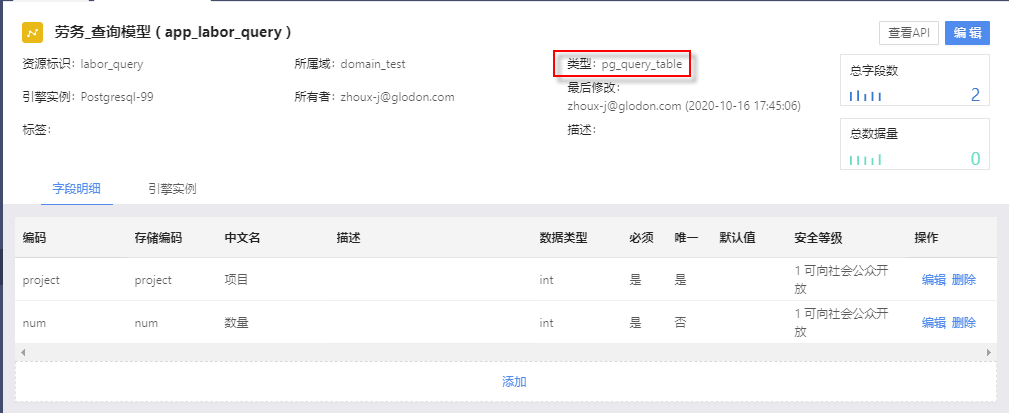
步骤二:在数据工厂中创建处理进程。

资源类型选择“pg_sql”,目标资源选择步骤一中创建的查询模型,并输入执行脚本,如上图红框所示,数据来源应为某个域内的pg_table数据表,即存有实际业务数据表。
- 离线任务
步骤一:创建pg_table数据资源。
步骤二:在数据工厂中创建处理进程。

资源类型选择“cron_task”,目标资源选择步骤一中创建的数据表,并输入执行脚本,如上图红框所示,数据来源应为某个域内的pg_table数据表,即存有实际业务数据表,并输入cron表达式。
6.2.5 数据服务
在数据服务中,能够以创建视图的形式,结合目录管理,对数据资源的关联关系进行可视化,从而便于用户调用对应资源的API。
关于数据服务的简易配置流程:

创建视图,需要填写视图的名字、编码和描述;

创建子节点,如下图所示,视图创建完成后即可在①根目录ROOT下创建子节点,之后每次创建子节点时,需要先选中所需创建子节点的上一级,再点击②创建子节点。

在下图中,即为创建视图节点的表单,除去名字、编码、描述等基本信息外,需要选择视图节点的类型,包括资源节点和目录节点两类。
资源节点即每个节点都有对应的数据资源存在,并与上(下)级中的资源节点存在对应的关联关系,图中③都是资源节点。
目录节点则没有对应的数据资源,其功能类似于索引文件夹,其下一级中的资源节点与上一级的资源节点存在关联关系,图中④2020年项目劳务人员即为一个目录节点。
数据资源一栏则可选择对应当前子节点关联关系的数据资源。
过滤设置一栏根据数据资源中的索引信息进行选择,没有则为空。
查看并调用API,选中某一资源节点后,则可看到其对应的基本信息和⑤API信息,点击即可复制。目录节点没有API信息。
6.2.6 API调用
数据资源API分为资源API和视图API,资源API又包括数据表(PostgreSQL查询模型、PostgreSQL数据集、Timeseries数据集、Greenplum数据集)和文件集两大类,以下使用POSTMAN工具演示API的调用过程。调用之前需将数据资源所在的域与应用进行绑定,获取应用Token后在Authorization中选择bearer Token,输入获取的Token即可进行调用。
(1)资源API
数据表
以PostgreSQL数据集为例,选择要调用的数据集,点击“查看API”按钮,共五类API,如下图所示:
1)查询数据-单条(GET)
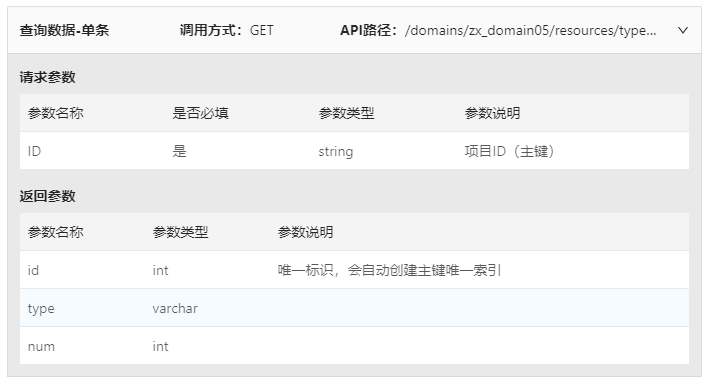
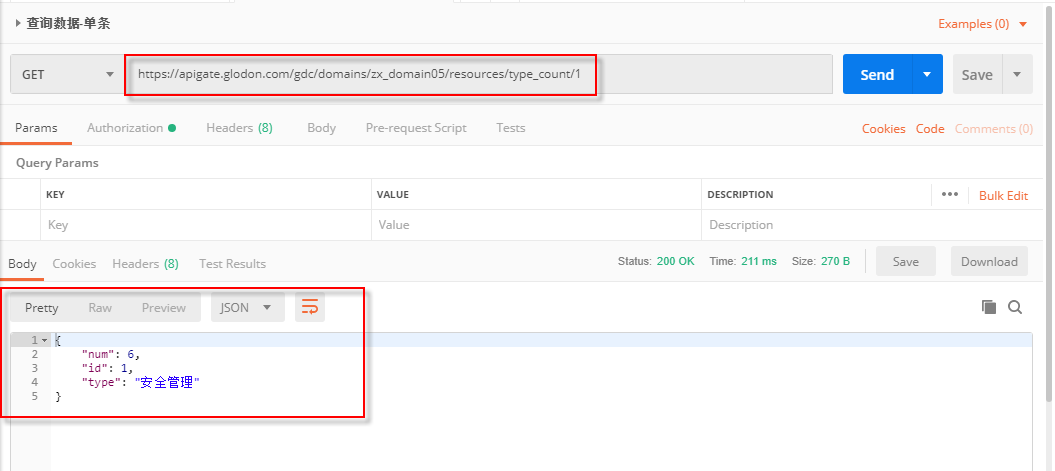
该API请求参数为主键ID,返回参数为该ID对应的记录,具体调用方式如下图所示,将“{ID}”修改为某一ID值,点击“Send”按钮即可在下方看到请求返回的数据。
2)查询数据-列表(GET)

该API通过索引过滤请求相应的列表数据,具体参数格式说明见上图。
利用该API调用时,需要先将过滤字段添加索引,这里以“num”索引字段进行过滤,筛选符合“num=6”的记录,结果展示为:
3)新增数据-列表(POST)

该API可批量新增数据,在body下填入数据(需为数组形式),点击“Send”按钮即可在结果栏中展示是否成功。(注:新增的数据需符合唯一字段的要求,否则会报错。)

4)更新数据-单条(PUT)
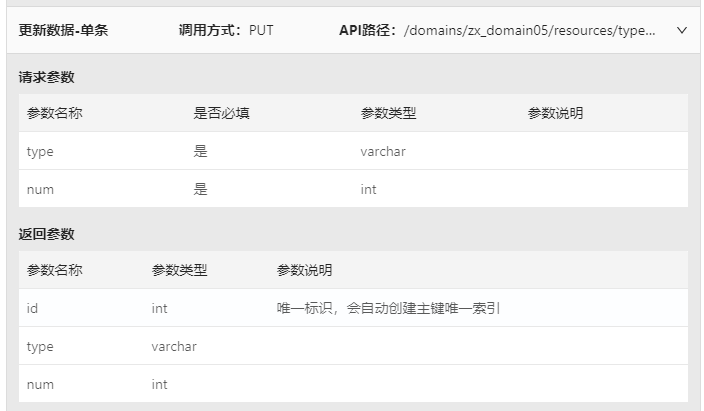
该API可根据主键更新对应字段信息,具体调用时需将URL中的“{ID}”修改为更新记录的ID,在body中填入其他字段的更新值,需为JSON格式。

5)删除数据-单条(DELETE)

该API可根据主键删除对应记录,具体调用时传入主键参数即可,结果栏中status返回“200 OK”即为删除成功,可在数据表中查到该条记录已删除。

查询模型无法设置主键及索引,目前仅支持查询数据,且返回所有记录行,不支持通过主键、索引进行过滤以及更新、删除数据。目前支持的查询如下图所示:

文件集
文件集与数据表的API相同,也包括五类,但具体调用内容又有所不同,数据表的返回值为相应的数据,而文件表的返回值是文件的元数据信息。
调用API之前新建文件集,然后导入文件,“目标数据集”选择当前新建的文件集,即可将多个文件导入文件集中。在该文件集中选择“数据预览”,可看到该文件集内包含文件的元数据信息,如主键、文件名称、文件大小等等,如下图所示:

1)查询数据-单条(GET)
该API请求参数为主键ID,返回参数为该主键对应的文件元数据字段,具体调用方式如下图所示,将URL中的“{ID}”修改为某个文件的主键值,点击“Send”按钮即可在下方看到请求返回的元数据信息。

2)查询数据-列表(GET)
该API通过索引过滤请求相应的文件信息,利用该API调用时,需要先将过滤字段添加索引,这里以“length”索引字段进行过滤,筛选符合“length>=200”的记录,如图所示,符合该过滤条件的文件大小有两个::
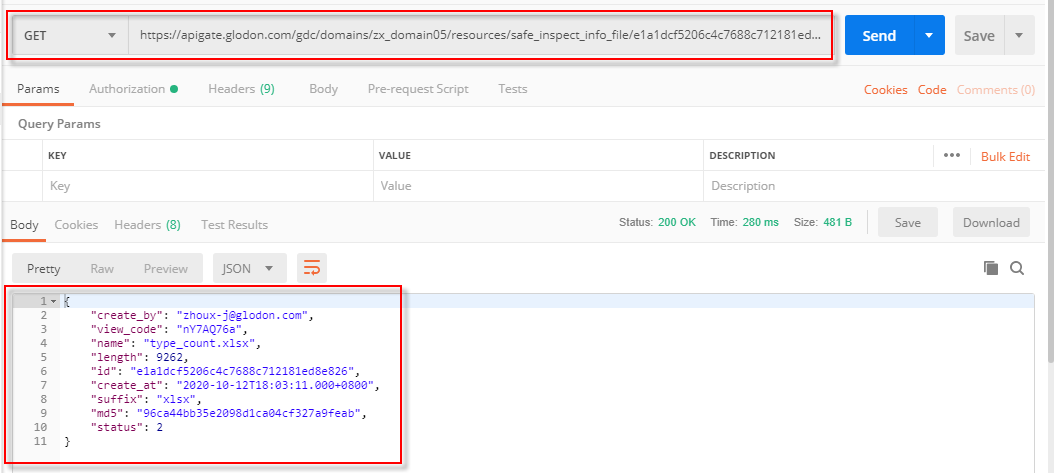
3)新增数据-列表(POST)

利用该API可批量新增文件,在body下填入请求参数(需为数组形式),这里的请求参数主要是文件的元数据,如上图所示,id、name、length、status为必填字段,点击“Send”按钮即可在结果栏中展示是否成功。 通过该API新增文件后,可在数据预览中查看该文件的元数据信息,但该文件实际内容为空。
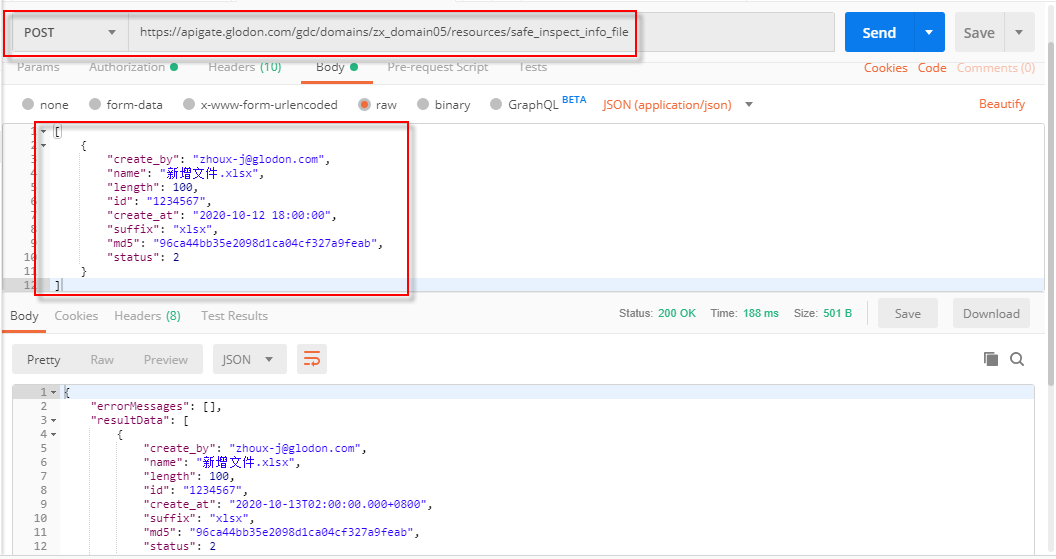
4)更新数据-单条(PUT)
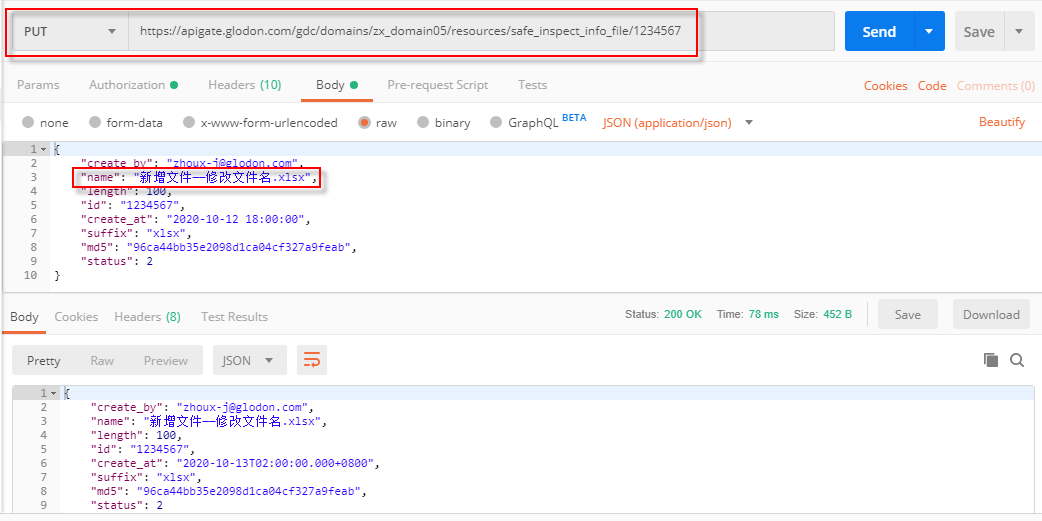
该API可根据主键更新某个文件的元数据信息,具体调用时需将URL中的“{ID}”修改为更新文件的主键ID,在body中填入其他字段的更新值,如下图所示。
5)删除数据-单条(DELETE)
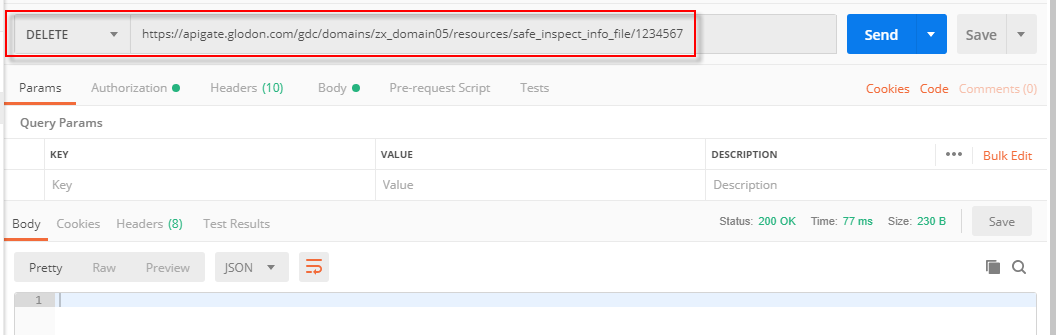
该API可根据主键删除对应文件,具体调用时传入主键ID即可,结果栏中status返回“200 OK”即为删除成功,可在文件表中查到该文件已删除。
(2)视图API
在数据服务中,能够以创建视图的形式,结合目录管理,对数据资源的关联关系进行可视化,从而便于用户调用对应资源的API。创建视图的步骤见6.2.5小节,节点类型分为目录节点和资源节点,目录节点无法调用API,以下均以资源节点演示API的调用。

如上图所示,共三个二级节点,点击节点可查看节点详情,包括API路径,红框中为三级节点“劳务(labor)”的API,可看到其路径中包含了父节点(项目)的信息,以调用劳务API为例:
1)查询数据-单条(GET)
查询单条数据的请求参数为项目和劳务两个数据表的主键ID,返回劳务表对应ID的记录。如需获取劳务表中项目ID为1以及劳务ID为3的劳务信息,其调用过程为:

2)查询数据-列表(GET)
查询列表数据的请求参数与资源API类似,通过索引过滤请求相应的数据信息,利用该API调用时,需要先将过滤字段添加索引,如需调用劳务表中A,B,C,D四个人中负责项目1的记录:

目前仅支持上述查询列表方法,即labor的父节点的请求参数只能为ID,不支持带过滤操作符的写法(可转换为ID写法进行调用)
3)新增数据-列表(POST)
该API可批量新增数据,API路径中需要填写project的ID,即新增数据中的项目ID,在body下填入数据(需为数组形式),点击“Send”按钮即可在结果栏中展示是否成功。(注:新增的数据需符合唯一字段的要求,否则会报错。)project后的参数不支持过滤操作符,因此一次批量新增数据中的项目ID需为同一值,若有不同值可分批新增。
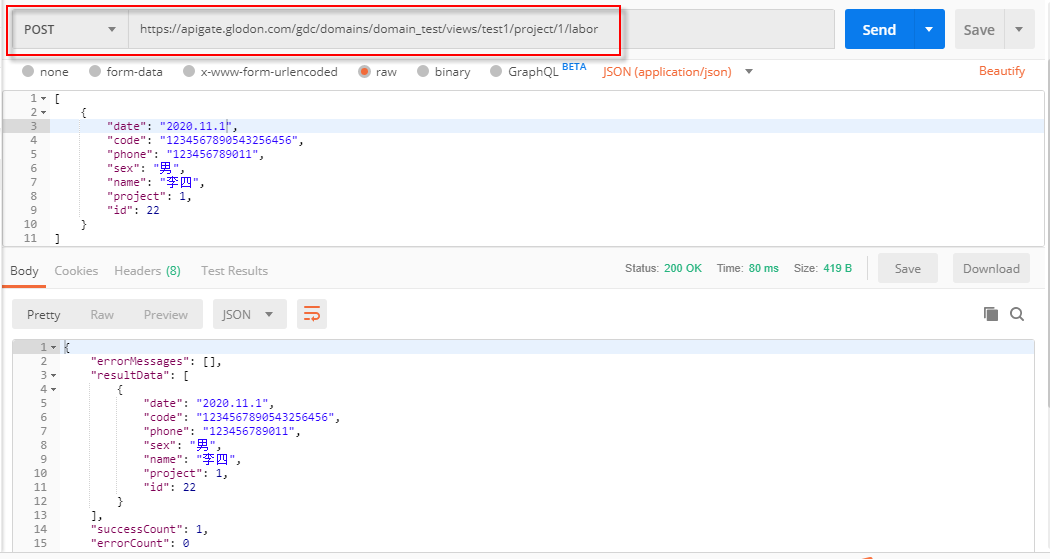
4)更新数据-单条(PUT)
该API可根据主键更新对应字段信息,具体调用时需将URL中的“{ID}”修改为待更新的项目ID,在body中填入其他字段的更新值,需为JSON格式。

5)删除数据-单条(DELETE)
该API可根据主键删除对应记录,具体调用时传入主键参数即可,结果栏中status返回“200 OK”即为删除成功,可在数据表中查到该条记录已删除。
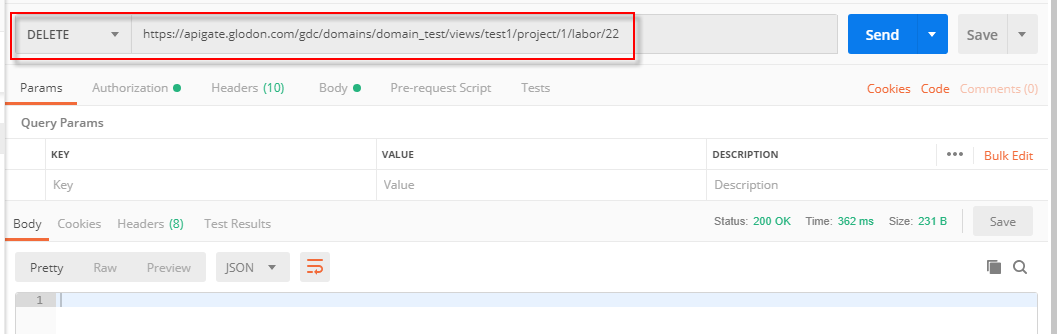
查询模型及时序数据等的调用与上述查询表的调用方法类似,但需要注意的是查询模型无法建立索引,因而不能通过API查询列表数据。
6.3 数据探查
通过该模块,可以在当前域中运行简单的SQL语句,并将运行结果进行显示,从而实现对数据进行探查。
目前支持SQL语句的运行、运行所选、格式化和转为离线任务(开发中),并支持将任务脚本转入至数据工厂(详见6.2.4)。
6.4 标签管理
对于数据资源信息中的标签信息,可以通过标签管理模块以目录的形式进行查看和管理。
标签间并无逻辑顺序,多级标签的格式是为了从用户角度梳理标签内容,便于管理和理解。此外,一个数据资源可以拥有多个标签,一个标签下也可以存在多个数据资源。
如下图所示,可以看到标签与数据资源之间的关系。
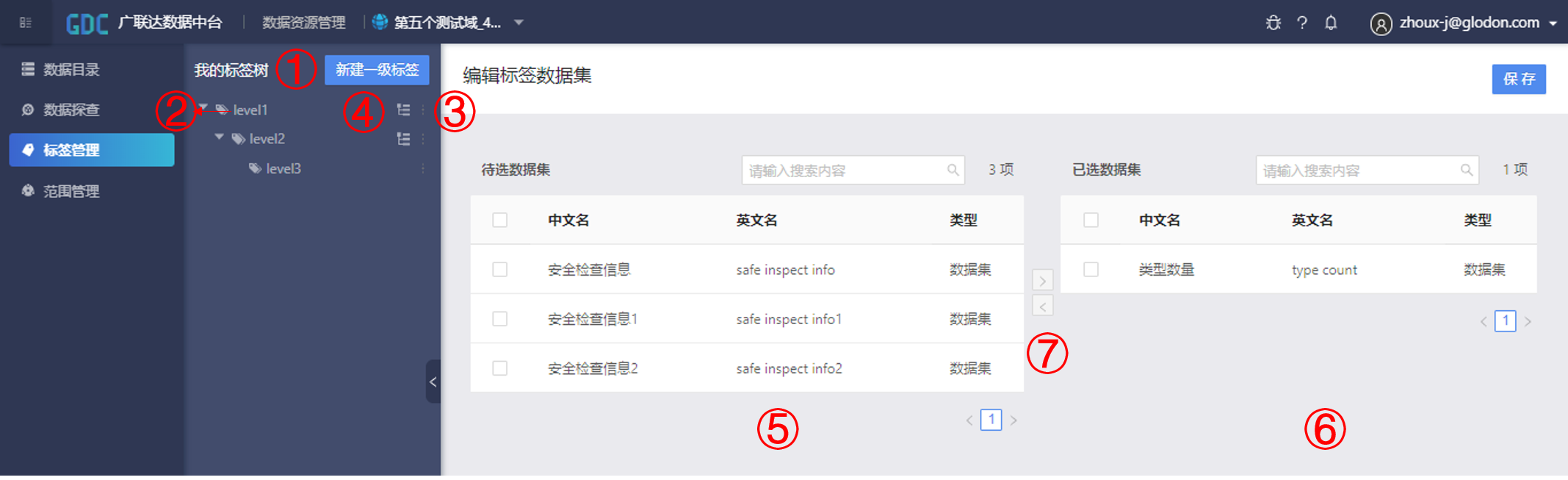
①“新建一级标签”,点击即可建立新的一个一级标签;
②标签名;
③点击该图标可编辑当前标签名,以及删除当前标签及其子标签;
④点击该图标,可在当前标签的下一级新建标签;
⑤已选数据资源,当前标签下已有的数据资源;
⑥待选数据资源,当前域下除去当前标签中已选数据资源的其他数据资源;
⑦“>”、“<”,通过这两个按键,可以对标签内的数据资源信息进行新增和删除。新增操作:在⑥待选数据中勾选需要添加到当前标签的数据资源,点击“<”,删除操作:在⑤已选数据资源中勾选当前标签中需要删除的数据资源,点击“>”。
6.5 范围管理
在域权限申请的过程中,域所有者、域管理员和开发可以通过范围管理模块,事先对申请者的申请范围进行定义,从而确保数据资源安全且高效的使用。
如下图所示,在范围模块中,可以看到当前域中的数据范围定义信息,包括来源(由哪个用户创建)、标识、中文名、维度表、显示字段、过滤操作符和过滤参数,并可对范围进行编辑和删除操作。
添加范围时也需要按照上文中的信息进行填写,范围操作符包括=、!=、>、>=、<、<=、between、in、not in。

图中显示的范围信息表示,当申请人在申请时,可对范围进行约束,即表示范围在“cpys730”域中的“cpys_table”表可以查看其中ID等于某值的范围(具体数值由申请者填写)。
随后可在数据目录中所需的数据资源进行编辑并添加范围,如下图所示。

在申请者申请该域权限时,选择支持范围限制,将会看到如下图所示。

以上图为例,配置范围后,再回到数据资源-数据目录进行数据预览,可见的数据范围即为之前申请的范围。

若多次申请同一资源表的权限,会按照资源id进行权限覆盖,即之前的权限无效,仅当前最新申请的有效。如上一次申请的某个字段表的权限为[ID:IN]=1,2,3,最新一次申请范围为[ID:IN]=4,5,6内,则用户当前的权限范围为最新一次申请的[ID:IN]=4,5,6。
# 附表
角色权限表
| 权限组 | 权限项 | 说明 | 域所有者 | 域管理员 | 开发 | 运营 | 匿名 |
|---|---|---|---|---|---|---|---|
| 域 | 列表 | 搜索到域名和描述 | √ | √ | √ | √ | 公共域和共享域 |
| 查看元数据 | 查看域基本配置页中所有数据 | √ | √ | √ | √ | 公共域和共享域 | |
| 维护基本信息 | 修改基本信息,业务信息,授权信息,自定义属性 | √ | √ | - | - | - | |
| 维护资源引擎 | 绑定,解绑引擎实例 | √ | - | - | - | - | |
| 维护非管理员 | 添加和维护非所有者和管理员角色 | √ | √ | - | - | - | |
| 维护管理员 | 添加和维护除所有者以外的所有角色 | √ | - | - | - | - | |
| 删除 | 将域置为删除状态 | √ | - | - | - | 公共域和共享域 | |
| 资源 | 列表 | 搜索到资源名和描述 | √ | √ | √ | √ | 公共域和共享域 |
| 创建资源对象 | 创建资源对象 | √ | √ | √ | - | - | |
| 查看元数据 | 查看资源详情页中所有数据 | √ | √ | √ | √ | 公共域和共享域 | |
| 删除资源对象 | 删除资源对象,包括元数据定义和内容 | √ | √ | √ | - | - | |
| 维护元数据 | 修改资源元数据 | √ | √ | √ | - | - | |
| 查询 | 查询资源内容 | √ | √ | √ | √ | 公共域和共享域 | |
| 编辑 | 更新资源内容 | √ | √ | √ | - | - | |
| 删除 | 删除资源内容 | √ | √ | √ | - | - | |
| 标签 | 查看 | 查看标签定义 | √ | √ | √ | √ | - |
| 维护 | 创建,删除标签,维护标签目录树 | √ | √ | √ | - | - | |
| 范围 | 查看 | 查看范围定义 | √ | √ | √ | √ | - |
| 维护 | 创建,修改,删除范围定义 | √ | √ | √ | - | - | |
| 服务 | 查看 | 搜索到服务名和描述 | √ | √ | √ | √ | - |
| 维护 | 开发新服务,修改服务定义 | √ | √ | √ | - | - | |
| 发布 | 发布新服务 | √ | √ | √ | - | - | |
| 运维 | 查看 | 进入运维控制台,查看所有数据 | √ | √ | √ | √ | - |
| 维护 | 维护任务,日志等 | √ | √ | √ | √ | - |
文件字段信息表
| 字段ID | 中文名 | 描述 | 数据类型 | 必须 | 唯一 | 默认值 | 安全等级 |
|---|---|---|---|---|---|---|---|
| id | 主键 | 文件对象唯一标识 | 字符型 | 是 | 是 | 1 可向社会公众开放 | |
| name | 文件名称 | 文件名称,对象集内不重名 | 字符型 | 是 | 是 | 1 可向社会公众开放 | |
| length | 文件大小 | 文件大小,单位字节 | 长整型 | 是 | 否 | 1 可向社会公众开放 | |
| md5 | 文件校验码 | 文件校验码 | 字符型 | 否 | 否 | 1 可向社会公众开放 | |
| thumbnail_url | 缩略图URL | 缩略图URL | 字符型 | 否 | 否 | 1 可向社会公众开放 | |
| status | 状态 | 文件状态 | 短整型 | 是 | 否 | 1 可向社会公众开放 | |
| create_by | 创建者 | 字符型 | 否 | 否 | 1 可向社会公众开放 | ||
| create_at | 创建时间 | 日期与时刻 | 否 | 否 | 1 可向社会公众开放 | ||
| update_by | 更新者 | 字符型 | 否 | 否 | 1 可向社会公众开放 | ||
| update_at | 更新时间 | 日期与时刻 | 否 | 否 | 1 可向社会公众开放 | ||
| suffix | 后缀名 | 字符型 | 否 | 否 | 1 可向社会公众开放 | ||
| view_code | 预览文件授权码 | 字符型 | 否 | 否 | 1 可向社会公众开放 |
数据资源批量导入说明页
| Sheet 说明 | **** |
|---|---|
| Sheet 1 | 说明页 (本页),不要做任何修改 |
| Sheet 2 | conf,资源类型及数据类型配置页,不要做任何修改 |
| Sheet 3 | 关联页,填写模型关联,关联格式为 源资源代码 + 源资源属性代码 + 关联资源代码 + 关联资源属性代码 |
| Sheet 4+ | 每一页一个模型定义 |
| 模型定义规则 | |
|---|---|
| 目标资源名 | 可以是中文,最少两个字符,最多20个字符 |
| 目标资源代码 | 只能是小写英文字母或者数字或者下划线,第一位必须是字母,最少2位,最多64位,例如 user_account |
| 目标资源英文名 | 可以是字母数字,最少两个字符,最多64个字符 |
| 目标资源描述 | 不超过200个字符 |
| 资源属性定义规则 | |
|---|---|
| ID | 一般模型都应该定义一个 ID / id 如果该模型仅仅是为了统计结果,可以不定义 ID. ID 字段的 code 必须是 id,一般类型都会选择 LONG,不能为空且唯一 |
| 属性名 | 可以是中文,最少两个字符,最多20个字符 |
| 属性代码 | 只能是小写英文字母或者数字或者下划线,第一位必须是字母,最少2位,最多40位,例如 user_name |
| 属性类型 | 请从属性类型的下拉菜单中选择,新创建的属性复制已有的下拉菜单即可,类型的含义请参考下面的类型列表 |
| 不能为空 | 该属性是否可能没有值,填写 Y 或者 N,代表 Yes 和 No |
| 是否唯一 | 该属性的值是否不可能有重复,填写 Y 或者 N,代表 Yes 和 No |
| 最大长度 | 加入属性为字符串类型,可选指定最大长度,例如 32 |
| 默认值 | 可选默认值,应兼容属性类型 |
| 属性描述 | 不超过200个字符 |
| 源属性代码 | 源属性代码 |
| Rename | 是否为关键字,改名 |
| GDCId | 是否为GDC主键 |
| 资源数据类型列表 |
|---|
| 参照config |
数据资源批量导入config表
| 数据库类型 | 资源类型 | pg_table | pg_query_table | ts_table | general_file | bim_model_file |
|---|---|---|---|---|---|---|
| mysql postgresql mongo | pg_table pg_query_table ts_table general_file bim_model_file | bigserial boolean varchar date real int json jsonb decimal serial time timetz timestamp timestamptz bigint | bigserial boolean varchar date real int json jsonb decimal serial time timetz timestamp timestamptz bigint | bigserial boolean varchar date real int json jsonb decimal serial time timetz timestamp timestamptz bigint | bigserial boolean varchar date real int json jsonb decimal serial time timetz timestamp timestamptz bigint | bigserial boolean varchar date real int json jsonb decimal serial time timetz timestamp timestamptz bigint |
数据资源批量导入字段信息表(以“主数据-企业级班组信息为例”)
| 源数据库类型 | 源数据库地址 | 源数据库编码 | 字符串连接参数 | 源表编码 | 数据库用户名 | 数据库密码 | 源数据库Pattern | 源表Pattern |
|---|---|---|---|---|---|---|---|---|
| mysql | ohb2fg-in-te-wl.mysql.rds. aliyuncs.com:3306 | master | zeroDateTimeBehavior= convertToNull&tinyInt1isBit=false | t_group |
| 目标资源编码 | 目标资源英文名 | 目标资源描述 | 目标资源类型 |
|---|---|---|---|
| master_group | master group | 保存企业级班组信息 | pg_table |
| 属性代码 | 属性类型 | 不能为空 | 是否唯一 | 最大长度 | 默认值 | 属性描述 | 源属性代码 | Rename | GDCId |
|---|---|---|---|---|---|---|---|---|---|
| id | bigserial | Y | Y | F_ID | 1 | ||||
| f_tenant_id | bigint | Y | N | 租户ID | F_TENANT_ID | ||||
| f_project_id | bigint | N | N | 项目ID | F_PROJECT_ID | ||||
| f_vendor_id | bigint | Y | N | 单位ID | F_VENDOR_ID | ||||
| f_team_id | bigint | N | N | 队伍ID | F_TEAM_ID | ||||
| f_name | varchar | N | N | 班组名称 | F_NAME | ||||
| f_type | int | Y | N | 0 | 班组类型;0:建筑工人班组;1:管理人员班组 | F_TYPE | |||
| f_work_type_id | bigint | N | N | F_WORK_TYPE_ID | |||||
| f_work_type_code | varchar | N | N | F_WORK_TYPE_CODE | |||||
| f_work_type_name | varchar | N | N | F_WORK_TYPE_NAME | |||||
| f_is_spec_work_type | boolean | N | N | F_IS_SPEC_WORK_TYPE | |||||
| f_leader_id | bigint | N | N | 班组长ID | F_LEADER_ID | ||||
| f_leader_name | varchar | N | N | 班组长 | F_LEADER_NAME | ||||
| f_leader_tel | varchar | N | N | 班组长电话 | F_LEADER_TEL | ||||
| f_deleted | int | N | N | 0 | 是否删除;1:删除 | F_DELETED | |||
| f_create_time | timestamp | Y | N | CURRENT_TIMESTAMP | 创建时间 | F_CREATE_TIME | |||
| f_update_time | timestamp | Y | N | CURRENT_TIMESTAMP | 修改时间 | F_UPDATE_TIME | |||
| sys_revision | bigint | N | N | 系统-乐观锁版本号 | sys_revision | ||||
| sys_create_time | timestamp | N | N | 系统-记录创建时间 | sys_create_time | ||||
| sys_modified_time | timestamp | N | N | 系统-记录修改时间 | sys_modified_time | ||||
| sys_creator_id | varchar | N | N | 系统-创建人 | sys_creator_id | ||||
| sys_modifier_id | varchar | N | N | 系统-最后修改人 | sys_modifier_id | ||||
| pdc_create_time | timestamp | Y | N | CURRENT_TIMESTAMP | PDC入库时间 |